Intro
This post is the 3rd as part of a container security series:
- Container Security - Defense in Layers!
- Containers from Scratch: Linux Isolation Primitives in Action!
- From Containers to Pods – Engineering Multi-Container Isolation
Goal
The goal of this 3rd post is to move from isolating a single process to managing multiple containers that communicate within isolated environments. At this stage, we cannot yet call it an orchestrator. Instead, it resembles a pod manager or a minimal orchestrator with basic lifecycle management.
For this to be called a real orchestrator in my POV it needs reliability. And Ill explain ‘why’ during in later sections of this post.
I’ll keep this post around the concepts instead of explaining my code, which is a mess haha
Short Disclaimer
Kubernetes follows a flat network model where Pods are routable by default unless restricted by NetworkPolicy.
In contrast, bctor (this project) treats the Pod as a namespace boundary: Pods are isolated at the kernel level, and no inter-Pod communication exists unless bridges or routing rules are explicitly configured.
This project explores namespace-enforced isolation rather than replicating Kubernetes’ networking model.
How containers communicate?
if we want to manage multiple containers, we need to answer a fundamental question:
How do containers communicate on Linux?
Recaping the first post of the series: Containers are just isolated processes.
So container-to-container communication is ultimately process-to-process communication, constrained by namespace boundaries
Process Communication in Linux (IPC Fundamentals)
Linux has multiples IPC mechanisms, lets focus on the ones we used during the project:
Pipes are unidirectional byte streams between related processes, typically parent/child after fork(). Its usually used for coordination, quick and small amount of data that can be used to set a sequence of actions.
- pipe()
- pipe2()
- read()
- write()
Sockets are bidirectional communication endpoints.. Very common in containers runtimes. With sockets we can send a more structured control message.
- socket(AF_UNIX….)
- bind()
- connect()
- sendmsg()
- recvmsg()
Q: OK! But what are u talking about? I just want to access a web server inside a container. Why do I care about pipes and sockets?
A: calm down. WE NEED Pipes and Sockets to send/get really necessary information in order to finally access another container via network
Q: GOOD, SO what are these important information?
We’ll get there..
WELL, lets start with. We need to join the network namespace..
A network namespace (netns) is an isolated instance of the Linux networking stack. When a process is placed inside a netns, it gets its own network interfaces, IP addreses, routing table etc
First we create the namespace:
clone(CLONE_NEWNET)
- The kernel allocates a new struct net
then in another process we join the created NS:
setns(fd, CLONE_NEWNET)
- now it switches its nsproxy->net_ns pointer to the same struct net
This is the underlying mechanism used by Kubernetes Pods. We will talk more about that later.
if we go deeper its not so simple
The kernel performs a series of capability and structural checks designed to prevent privilege escalation and cross-namespace abuse. Namespaces are objects owned by the kernel, and every namespace is tied to a user namespace that defines who has authority over it.
The first rule is to be in the same network (or any other namespace) we need to be in the same USER NS (or be in parent user namespace that has sufficient capabilities).. Doesnt matter if you are ROOT, if the process are in another USER NS you cant join.
Second rule concerns namespace type restrictions. Some namespaces have structural constraints. For example, a PID namespace cannot be joined with setns() in the same way as a network namespace. Entering a PID namespace only affects future children, so it must be done during clone(CLONE_NEWPID) and followed by a fork. The kernel enforces this because PID visibility is fundamental to process hierarchy. Similarly, certain namespace transitions are blocked if the calling task is multithreaded, because namespace membership is stored in the shared nsproxy structure and inconsistent switching would break invariants.
lets go back one step
How one process gives another process access to a namespace?
A namespace is represented in userspace through a special file descriptor that refers to /proc/<pid>/ns/<type>. For a network namespace, that path is /proc/<pid>/ns/net.
Helper used to get the correct path based on the namespace:
func nsTypeToProcPath(ns NamespaceType) string {
switch ns {
case NSUser:
return "/proc/self/ns/user"
case NSNet:
return "/proc/self/ns/net"
case NSMnt:
return "/proc/self/ns/mnt"
case NSPID:
return "/proc/self/ns/pid"
case NSIPC:
return "/proc/self/ns/ipc"
case NSUTS:
return "/proc/self/ns/uts"
case NSCgroup:
return "/proc/self/ns/cgroup"
default:
LogError("nsTypeToProcPath")
panic("unknown namespace type")
}
}
This is not a normal file! it is a reference to a kernel namespace object. When you open it, you obtain a file descriptor that points to that namespace instance. That file descriptor is what setns() consumes.
The FD pins the namespace object in memory as long as it remains open
Q: we need to pass file descriptors between processes?
Exactly! When one process creates a new namespace with clone(CLONE_NEWNET), only that process initially has a reference to it. If another process needs to join it, it must obtain a file descriptor that references the same namespace object.
btw when I say CREATOR, im refering to the process that created the namespaces. JOINERS are the processes that will join the creator resources basically..
Thats where the Sockets come in to play.. The creator passes the already opened namespace file descriptor through a UNIX domain socket using sendmsg() with SCM_RIGHTS
We can reference the PID too and make the JOINER get the full path /proc/<pid>/ns/net. But passing the FD (in this case) is safer, cause even if the creator exits, the namespace will persist as long as at least one FD still references it. This doesnt work well otherwise .. if we pass the PID, in case the creator dies, we cant open the “directory” of the NS object.
K8s for example creates a PAUSE CONTAINER that works as anchor for the workloads. In this case, there is no need for FD passing. The namespace persists because at least one process (the pause container) is always attached to it. If the pause container exits, the Pod is terminated.
From kubernetes repo, the pause container:
int main(int argc, char **argv) {
int i;
for (i = 1; i < argc; ++i) {
if (!strcasecmp(argv[i], "-v")) {
printf("pause.c %s\n", VERSION_STRING(VERSION));
return 0;
}
}
if (getpid() != 1)
/* Not an error because pause sees use outside of infra containers. */
fprintf(stderr, "Warning: pause should be the first process\n");
if (sigaction(SIGINT, &(struct sigaction){.sa_handler = sigdown}, NULL) < 0)
return 1;
if (sigaction(SIGTERM, &(struct sigaction){.sa_handler = sigdown}, NULL) < 0)
return 2;
if (sigaction(SIGCHLD, &(struct sigaction){.sa_handler = sigreap,
.sa_flags = SA_NOCLDSTOP},
NULL) < 0)
return 3;
for (;;)
pause();
fprintf(stderr, "Error: infinite loop terminated\n");
return 42;
}
K8s model:
Container Runtime
│
(1) Create Sandbox (NetNS)
▼
Pause Container (PID 1 in Pod)
│
┌───────────────┴───────────────┐
│ (2) Join NetNS, IPC, UTS │
▼ ▼
[ Workload A ] [ Workload B ]
(e.g. Nginx) (e.g. Python App)
I choose to do the hard way cause it really exposes the kernel mechanics.. We can “see” each step clearly and sequencially. K8s model is easier to implement and better tho, it decreases the cross-container coordination.
In Docker model its different:
Each container gets its own separate net namespace (by default), and Docker connects them using a bridge + veth pair model
Host Namespace
┌──────────────────────────────────────────────┐
│ │
│ docker0 (bridge) │
│ 172.17.0.1/16 │
│ │ │ │
│ │ │ │
│ vethA-host vethB-host │
│ │ │ │
└────────────────┼────────────┼────────────────┘
│ │
▼ ▼
┌─────────────────┐ ┌─────────────────┐
│ Container A │ │ Container B │
│ netns A │ │ netns B │
│ eth0: 172.17.0.2│ │ eth0: 172.17.0.3│
└─────────────────┘ └─────────────────┘
You can force them to be in the same network namespace tho with the command:
docker run --network=container:<id>
CREATOR and JOINERS
We really gotta separate tasks going forward, some processes are creators, and some are joiners. We must be very clear when organizing the order of execution.
for the JOINER the setns() must happen before unshare(). BUT the creator of the namespace doesnt call setns() because it creates the namespace directly using clone() or unshare() with the appropriate CLONE_NEW flags.
Now about user namespaces… they require special clarification. User ID mappings (uid_map, gid_map) are only necessary when you create a new user namespace with clone(CLONE_NEWUSER) or unshare(CLONE_NEWUSER). The kernel starts that namespace with no ID mappings. Until mappings are written to /proc/<pid>/uid_map and /proc/<pid>/gid_map, the process effectively has no meaningful privilege translation. If you are merely joining an existing network namespace and not creating a new user namespace, you do not need to perform any UID/GID mapping.
File descriptor transfer design
As we said a namespace is entered via a file descriptor that references /proc/<pid>/ns/net. That FD must exist in the process that calls setns().
SCM_RIGHTS allows sending that FD over a UNIX domain socket, but OOONLY between processes that already share a connected UNIX socket. Two isolated containers do not automatically share such a control channel. They may share a network namespace, but that does not imply a shared UNIX socket or filesystem path usable for FD passing.
In the screenshot below we can see that there are 2 containers (creator, joiner). They both share the same USER NS and NET NS, therefore they share the same network:
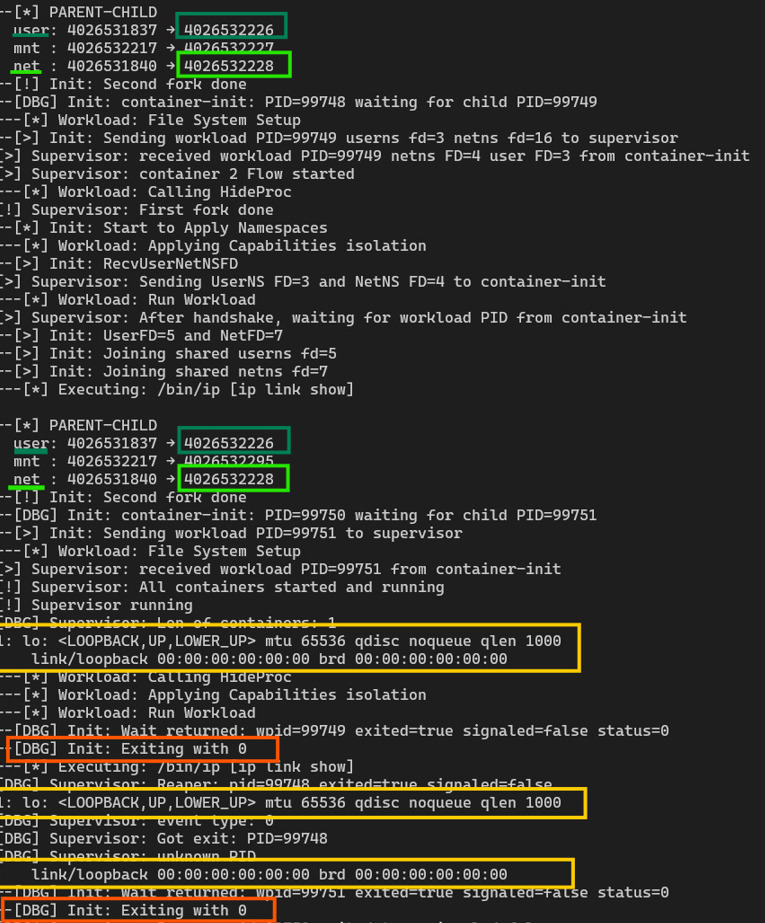
The supervisor runs outside the container namespaces, in the parent user namespace, holding full privileges. It creates the namespace, opens the namespace FD, and maintains UNIX socket connections to each container process during bootstrap. When container-1 creates or owns a namespace, it may send the FD to the supervisor. The supervisor then forwards that FD to container-2 over its own control socket. The containers do not directly exchange namespace handles because there is no guaranteed secure communication path between them at that stage of setup.
In the screenshot above we can see the file descriptors passing from container-1 > Supervisor > container-2
There is also a lifecycle reason. The supervisor can keep the namespace FD open, pinning the namespace in the kernel even if the original creator exits. Namespace objects are reference-counted. If no process and no FD references them, they are destroyed. By holding the FD centrally, the supervisor guarantees namespace persistence across container restarts or partial failures.
Bctor model is working like this:
Supervisor
│
┌─────────────┼─────────────┐
▼ ▼
container-init A container-init B
│ │
workload A workload B
and the namespace flow:
container-init A
│
create netns
│
open /proc/self/ns/net → send FD → Supervisor
│
▼
forward FD to container-init B
│
setns(netns)
│
spawn workload B
“in pretty terms” this is a distributed namespace ownership model
Execution Modes
Once networking and namespace sharing are solved, the next architectural concern is how workloads are executed and observed.
A container runtime must support at least two execution modes:
- Batch (non-interactive)
- Interactive (TTY-attached)
type ExecutionMode int
const (
ModeInteractive ExecutionMode = iota
ModeBatch
)
type WorkloadSpec struct {
Path string
Args []string
Env []string
Mode ExecutionMode
}
And before discussing execution modes, it is necessary to understand what a PTY is and how it behaves inside the Linux kernel.
What is PTY
PTY or pseudoterminal. It’s a pair of connected virtual devices that emulate a real hardware terminal. The pair consists of a master side and a slave side. The slave behaves like a real TTY device from the perspective of a process. When a process opens the slave device, performs setsid(), and assigns it as its controlling terminal using ioctl(TIOCSCTTY), the kernel attaches terminal semantics to that session.
I tried to do both OUTPUT and INPUT via Socket but only the OUTPUT worked well
Thats for a lot of reasons, but mainly because prompt formatting. WHen I was using the sockets for INPUT, it was a mess. I entered a rabbit hole trying to solve inumerous problems that wasnt really necessary to solve if I used PTY since the begining.
Well, I had to give 2 steps back and switched to PTY
Many interactive programs explicitly check whether their standard streams are attached to a TTY via isatty(). If they are not, they disable features such as prompts, line editing, or colored output. It’s what happened when I was using pipes/sockets for this, thats the reason PTY is required for interactive container execution.
Interactive Mode
In interactive execution mode, every container is provisioned with a PTY master/slave pair during its IPC setup. The workload-side init process creates a new session using setsid(), opens the slave device, and claims it as the controlling terminal. It then duplicates the slave file descriptor over stdin, stdout, and stderr using dup2() before calling execve() to launch an interactive shell
func setupInteractiveIO(ipc *IPC) {
sFd := int(ipc.PtySlave.Fd())
mFd := int(ipc.PtyMaster.Fd())
// New session and controlling TTY for interactive shell.
_, _ = unix.Setsid()
_ = unix.IoctlSetPointerInt(sFd, unix.TIOCSCTTY, 0)
_ = unix.Dup2(sFd, 0)
_ = unix.Dup2(sFd, 1)
_ = unix.Dup2(sFd, 2)
unix.SetNonblock(0, false)
unix.SetNonblock(1, false)
unix.SetNonblock(2, false)
// Close originals
if mFd > 2 {
unix.Close(mFd)
}
if sFd > 2 {
unix.Close(sFd)
}
}
From the shell’s perspective, it’ss attached to a real terminal device
The kernel enforces session semantics, signal routing, foreground process groups, and terminal-generated signals correctly.
The supervisor maintains a mapping between containers and pty master and it runs a raw-mode input loop in its own controlling terminal so that keystrokes are forwarded byte-for-byte to the currently attached container’s PTY master.
Batch mode
Batch execution mode is little bit different. Instead of attaching a PTY, stdout and stderr of the workload are redirected to a dedicated logging channel, that was implemented using the domain socket connected to the supervisor
func setupBatchIO(ipc *IPC) {
// Redirect stdout/stderr to pipe
unix.Dup2(ipc.Log2Sup[1], 1)
unix.Dup2(ipc.Log2Sup[1], 2)
// Close unused ends
unix.Close(ipc.Log2Sup[0])
unix.Close(ipc.Log2Sup[1])
}
A dedicated goroutine reads from the log file descriptor and line-buffers the output into structured log records. These records are sent through a global logger that serializes rendering.
Its kinda boring, but without the serialization doesnt matter if we are not using interactive mode, because containers and commands results are concurrently it will totally produce unreadable output.. And worse it will, mix results from one container to another..
Result of the modes
Interactive and batch modes therefore differ not only in I/O wiring but in semantic expectations. Interactive is used by default, because the default of a container (in this case) is a process with applied namespaces that we can access its shell. While batch treats execution as a pure data stream with structured log capture, meaning that it works well for commands that has a rapid end of execution and give us an result output imediately..
I did some profiles so that I can apply both the MODES and the SECCOMP rules:
var WorkloadRegistry = map[Profile]WorkloadSpec{
ProfileDebugShell: {
Path: "/bin/sh",
Args: []string{"sh", "-i"},
Env: []string{
"PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin",
"TERM=xterm-256color",
"HOME=/root",
},
Mode: ModeInteractive,
},
ProfileIpLink: {
Path: "/bin/ip",
Args: []string{"ip", "addr", "show"},
Env: []string{"PATH=/bin:/sbin:/usr/bin"},
Mode: ModeBatch,
},
...
For example command “ip addr show” shows that both containers share the same network namespaces, which demonstrate that they have the same interface. And the output is organized enough that we can add a pretty box to separate content.
Batch mode command result:
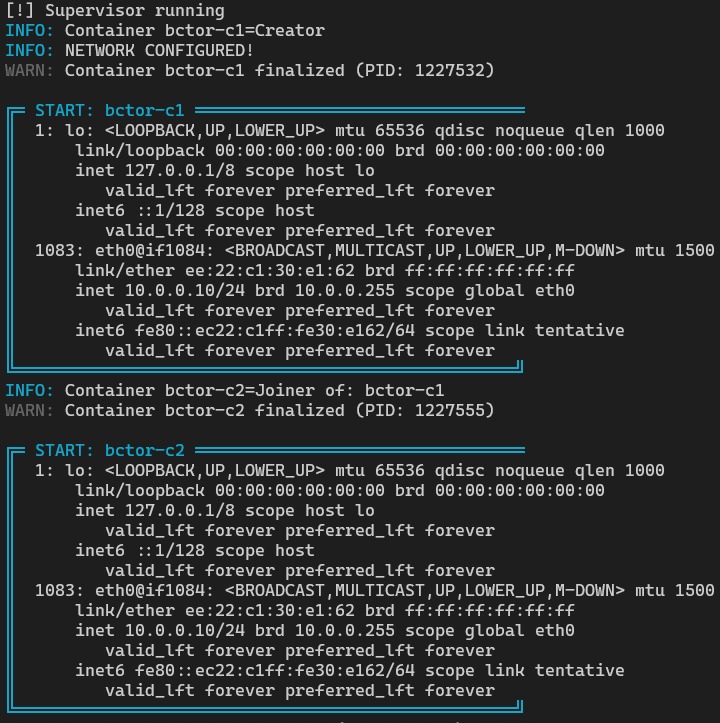
Pod Management and Network
Now we have isolation, multiple containers that can communicate with each other through them being in the same network NS. We can turn this into a Pod management to be able to have even more control over the containers and their relationship.
What is a Pod?
“A Pod is similar to a set of containers with shared namespaces and shared filesystem volumes” - From Kubernetes.io
The architecture has evolved to be pod-centric. The pod is the boundary for shared namespaces between containers and the unit that owns namespaces, network identity, and lifecycle. Containers are simply processes that join an existing pod context.
Networking starts with a single container designated as the net-root (creator in this case). This container creates and owns the network namespace for the pod. During setup, the supervisor creates a virtual ethernet (veth) pair, which acts like a physical patch cable.
One end stays on the host and is attached to a bridge device. The other end is moved into the pod’s network namespace. Inside that namespace, the interface is brought up and assigned an IP address. Routing and link state are configured at this stage. After that, the pod has a fully functional network stack.
INTERNET
|
|
[ HOST eth0 ]
|
(iptables MASQUERADE)
|
---------------------
| bctor0 |
| 10.0.0.1/24 |
---------------------
| |
veth-pod1-host veth-pod2-host
| |
veth-pod1-ns veth-pod2-ns
| |
-------------------- -------------------
| Pod A NetNS | | Pod B NetNS |
| IP: 10.0.0.2 | | IP: 10.0.0.3 |
| | | |
| Container A1 | | Container B1 |
| Container A2 | | Container B2 |
| Container A3 | | Container B3 |
-------------------- -------------------
If one container binds to 0.0.0.0:8080, the port is occupied for the entire pod. If one container opens a connection, it originates from the pod IP. The network identity is pod-scoped.
When the last container exits and the pod becomes empty, forwarding rules are removed, the veth pair is deleted, and the IP address is released. Cleanup is automatic because it is tied to pod lifecycle, not container lifecycle.
This mirrors Kubernetes pod-level networking semantics, but networking is configured directly through Linux primitives instead of a pluggable CNI interface.
And that is the final result:
now we can create Pods with any amount of container we want:
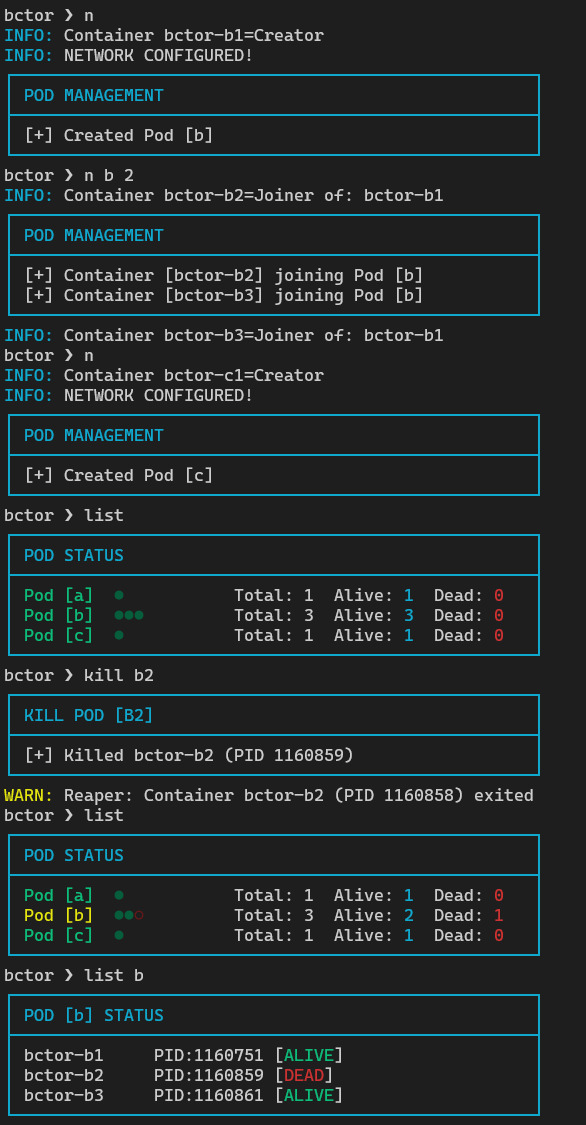
We can use forward (proxy) if we want to connect host with the container network:
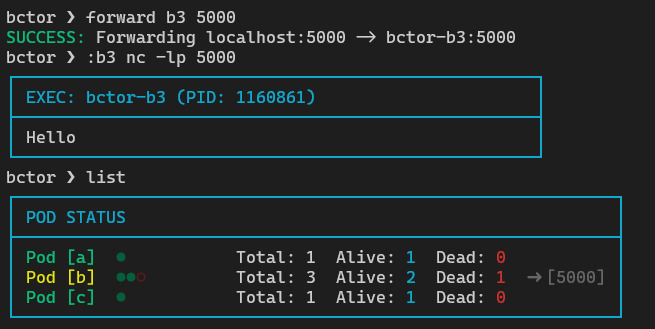

we can destroy the whole Pod and everything inside, consequently:
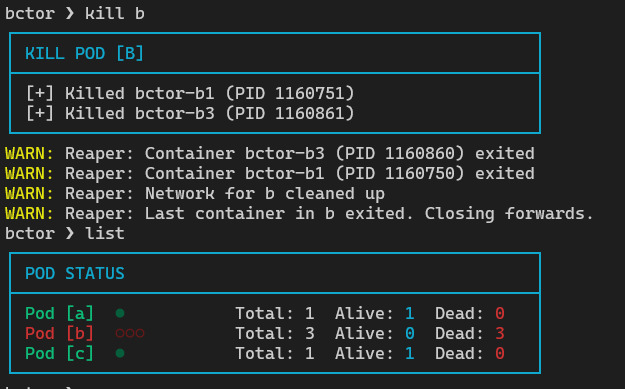
One thing to look out is about the chosen architecture.
The core implementation decision is centralized ownership. The supervisor OWNS everything basically… namespace FDs, IO routing, and teardown authority. Containers do not create or destroy namespaces independently. They are admitted into a pod through explicit IPC and FD passing. The supervisor tracks membership and reference counts. When processes exit, a centralized reaper processes events and determines whether only a workload died or the entire pod has terminated.
And because everything is centralized on the supervisor we have a problem of reliability.. Which is what our last chapter is about
Reliability
WELL, this architecture is efficient and well suited for testing environments cause it’s lightweight and centralized. HOWEVER letting the Supervisor responsible for the most important jobs of the architecture is dangerous.
that same centralization introduces a structural risk: a single point of failure.
If the supervisor process terminates unexpectedly, the system loses the entity that owns and manages every resource inside, Pods, containers, network whatever
Closing a NS FD doesnt immediately destroy a namespace if processes still exist inside it, but if the supervisor was the last holder of a reference for a namespace that no process remains attached to, that namespace is destroyed.
The same happens, if the supervisor is responsible for network devices and forwarding rules, an abrupt exit may leave inconsistent state or orphaned configuration.
In this model, all orchestration authority is concentrated in one parent process.
there is no redundant control plane
How K8s does it
In large-scale systems such as Kubernetes, this risk is mitigated by separating responsibilities. The kubelet, container runtime, control plane components, and networking plugins are distinct processes.
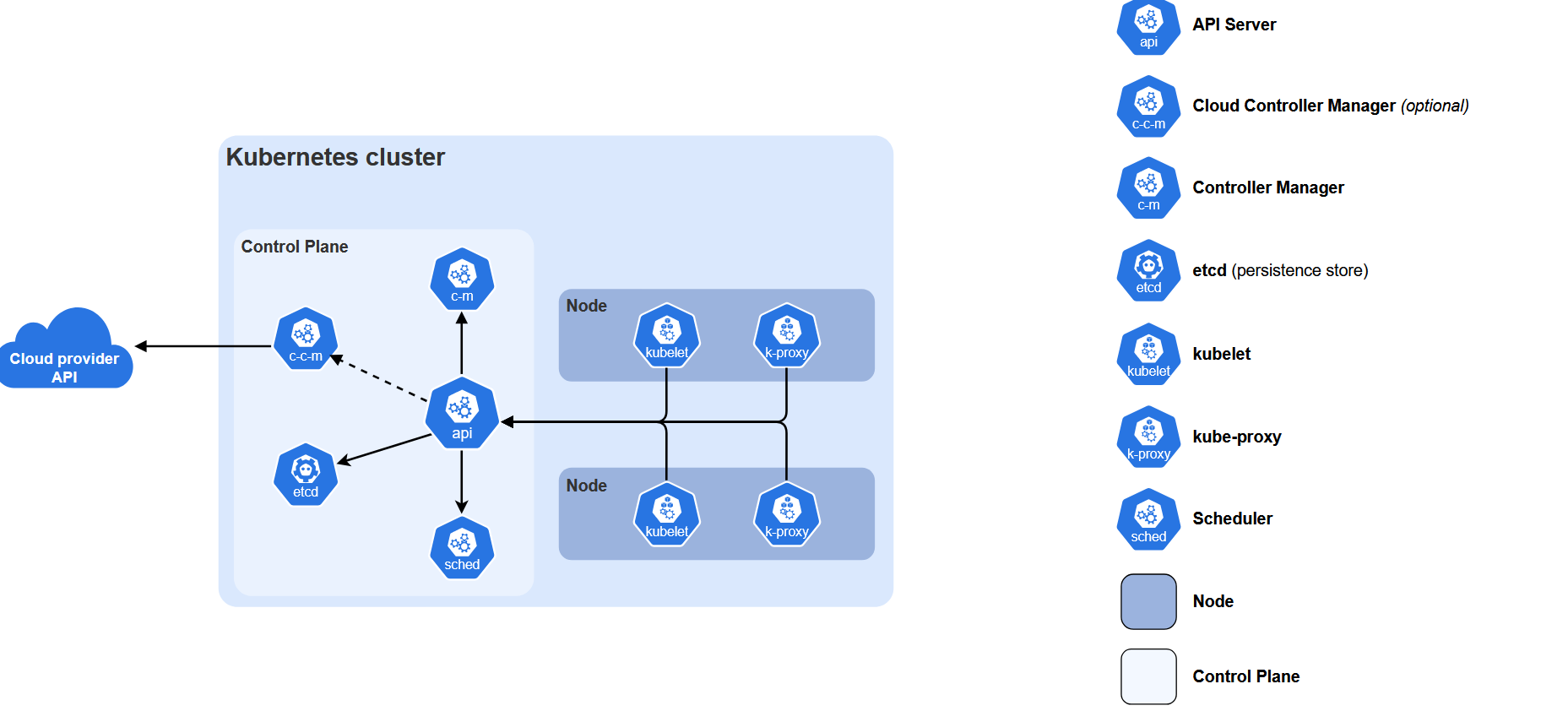
The failure of one does not necessarily terminate running containers immediately. In our architecture, the supervisor is both “runtime manager” and “control authority”, so its availability directly impacts the system.
There are a lot of strategies of how improve reliability, some examples:
- The supervisor can be made minimal and stateless
- We could do a persisting pod state so that a restarted supervisor can reconstruct in-memory structures
- Namespace and network cleanup routines can be done separetely
- maybe a YML file with all config of containers used etc
in summary we gotta replicate the orchestration authority
In this new model its ok if the supervisor dies, or the Pod dies.. anything can be restarted shortly or reconstructed. Thats the difference from production level systems. I recognize that our program is far from it, but its still a good model for experimentation.
What’s next?
there are a lot of things to improve in the project. reliability is only one of them.. but here i’m prioritazing learning and what can give me and the readers more return of the time invested.
I think its only fair for a next post to be about eBPF and how it compares with the classic seccomp-BPF that we implemented in this project.
Check the repo of this project: BCTOR GITHUB REPO
Follow me on github and Linkedln if this post was anyway useful!
Hope you liked! :D
References
IPC / Pipes
UNIX Domain Sockets
Namespaces / Process Creation
Networking
File Descriptors
SCM_RIGHTS / FD Passing
PTY / Terminal Control
Execution
Kubernetes References
- Pods
- Pod Lifecycle
- Container Runtime Interface (CRI)
- Pause Container Source
- Kubernetes Components Overview
CNI
Docker References
- Docker Networking Overview
- Docker Bridge Network Driver
- Docker Run — Network Settings
- Docker Engine (dockerd)